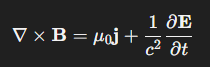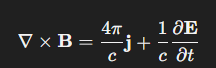有些人在做 side project,故意用寫得很漂亮、很舒服的排列方式,享受 code 本身的美感,也算 vibe coding。
GPT5 – 形容「隨興、輕鬆、無壓力地寫程式」的方式或心態。
1️⃣ 正規 Coding(較嚴謹):
def add(x: int, y: int) -> int: """ 回傳 x 和 y 的加總 """ return x + y
2️⃣ Vibe Coding(隨手寫):
add = lambda x, y : x + y
或者乾脆邊寫邊想,沒規劃好就隨機調整程式,重在隨心所欲。
Gemin 3 Pro – 比較接近我想的樣子。
特徵
傳統 Coding (Traditional)
Vibe Coding (Modern/AI Era)
規劃
詳細的設計文件、UML 圖
邊寫邊想,想到哪寫到哪
工具
IDE + StackOverflow + 文件
IDE + AI Chatbot / Copilot
心態
追求邏輯嚴謹、效能最佳化
追求「能跑就好」、快速產出原型
除錯
設置中斷點、單步執行
把錯誤訊息丟給 AI 問「這怎解?」
重點就在於講到了 AI 這個 Keyword。這年頭,沒 AI 怎麼算是 vibe 呢?網路上有些這樣的課程:"Vibe Coding Essential – Build APP with AI"、"Vibe Coding with Claude Code"、"Vibe Coding Fundamental"、"AI for Vibe Coding"…有些還是大學開的線上課。
在 Command line 的領域,當然的就是 Claude Code 了。它的 Pro 版本月租費跟 Cursor Pro 一模一樣。另外它也有 VSCode 的插件版本,不過那樣就不帥了。Claude Code 終端機只要開一個視窗,下面 “>" 符號後面用文字輸入你的需求,上面就刷刷地跑程式。看起來這也是它沒有辦法支援 Android 沙箱的原因。
Claude Code 在提示符號下打 /model,就可以看到裡面預設 3 個 Anthropic 的 model 可以切換: