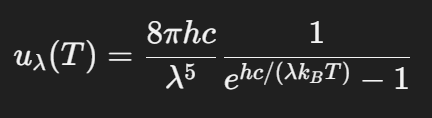量子力學之所以不能像傳統物理一樣用明確的公式解決因果關係,有人認為一定是某個變數沒有被發現,一般稱之為隱變數 (hidden variable,或稱隱變量)。那隱變數是否存在呢?
[存在派] 1927 年,德布羅意波提出相位波之後,又提出一個新的導波理論 ( pilot-wave theory)。它的核心理論是 “粒子始終有確定位置,只是它的運動被一個波函數導引。"只是我們不知道它的精確初始條件,所以看起來呈現機率。這就非常符合「隱變數」的精神。
[否定派] 1932 年,馮諾曼 (John von Neumann,就是計算機結構那位) 證明隱變數不能解釋量子論的隨機性。他一共提了五個假設,數十年間都沒有人指出其中顯而易見的 bug。
[存在派] 1952 年,大衛·波姆 (David Bohm,就是改寫 EPR 為自旋版本的那位) 指出馮諾曼第五個假設是錯的。馮諾曼的版本是:
對一個態向量 Ψ 進行 X 觀察,坍陷的的期望值為 <X,Ψ>。再做一次 Y 觀察,坍陷的的期望值為 <Y,Ψ>,則假設: <X+Y,Ψ> = <X,Ψ>+<Y,Ψ>。
要是世界上有隱變數, <X+Y,Ψ,H> = <X,Ψ,H>+<Y,Ψ,H>….
波姆說 H 不能拿去平均,X 擲骰子平均 3.5 點, Y 擲骰子平均 3.5 點,不代表 X、Y 一起擲骰子加起來是 7 點。因為假設錯了,這個證明無效。
不光是證明別人錯就好。波姆把導波換成量子勢 (quantum potential),說粒子有這個勢,所以可以感應到雙縫的存在,因此粒子隨之產生微妙的變化。不過這個說法雖然 “勢在必行"、"勢不可擋",卻等於同時承認了超距力。
換言之,就算我們要看遙遠的星河的光有沒有通過雙縫,雙方都要產生超光速的感應才行。學術地說,他的理論破壞了 “定域性" (locality),說服力不足。
[一個 patch] 1964 年,約翰·斯圖爾特·貝爾 (John Stewart Bell) 證明了任何想要重現量子力學結果的隱變量理論,都不能是定域的。他怎麼證明呢?書上有很長的說明 (p. 288~p.292),我們講一些好懂的。
假設一對糾纏的粒子 A 和 B 分別分到宇宙的兩端。由 Alice 測量粒子 A,Bob 測量粒子。
[愛因斯坦版] 兩個粒子分手前,已經帶的標準答案離開,Alice 測量 A,並不會影響 Bob 測量 B。
[波姆版] Alice 測量 A 時,B 就發現了,所以會影響 Bob 的測量。
[貝爾版] 假如 A、B 各自帶著標準答案離開的話,以單純的機率來說, Alice 和 Bob 的統計相關性會有個上限。其中,P 是機率,Pxy 代表粒子 A 在 x 軸為 +,且粒子 B 在 y 軸也為 + 的機率。
|Pxz – Pzy| ≦ 1 + Pxy
貝爾不等式簡單地證明了,在定域隱變數理論下,某些實驗統計結果不能超過某個數值。反之,如果統計結果突破了貝爾不等式的上限,定域隱變數就不存在。
隨著科技的進步,科學家已經可以用實驗重現 EPR 的推論。不意外地,實驗愈精準,偏離貝爾不等式愈多。
要嘛承認沒有隱變數、要嘛承認超距力 (還不等於超光速),兩者愛因斯坦都不能接受,不過這也沒辦法。貝爾本來想要加持隱變數一脈,結果貝爾不等式反而背刺了老前輩。
[GHZ 測試] 貝爾不等式雖然只用國中數學和兩個粒子就能解釋,但是世界在進步。後起之秀 Greenberger、Horne、Zeilinger 又證明了 3 個以上的粒子糾纏時,也和定域隱變數不相容。
在此先告一段落,沒有定域隱變數 (局域隱變量),結案。
[REF]
- 本書勘誤, p. 292, 1 印成 |,把貝爾不等式印錯了。
- 本書勘誤, p. 293, 1 印成 |,把貝爾不等式印錯了。