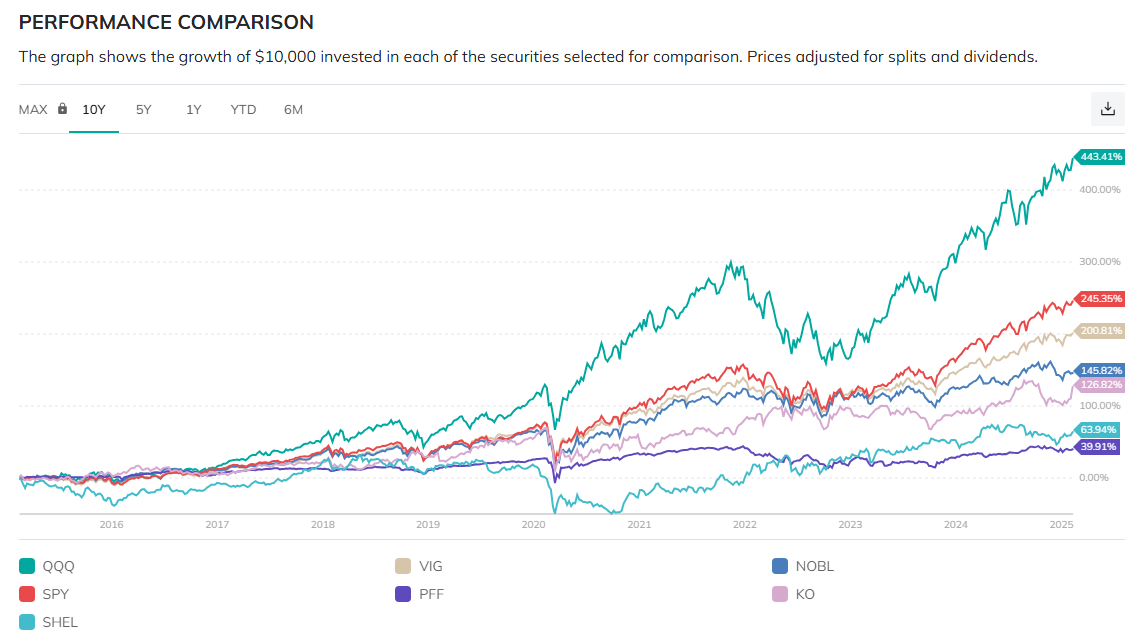
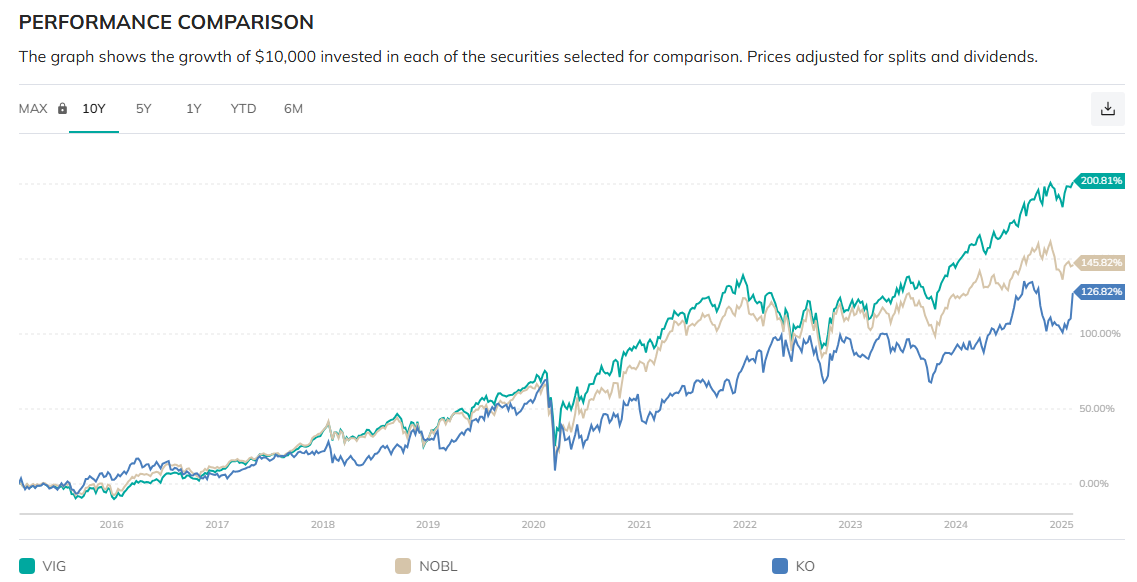
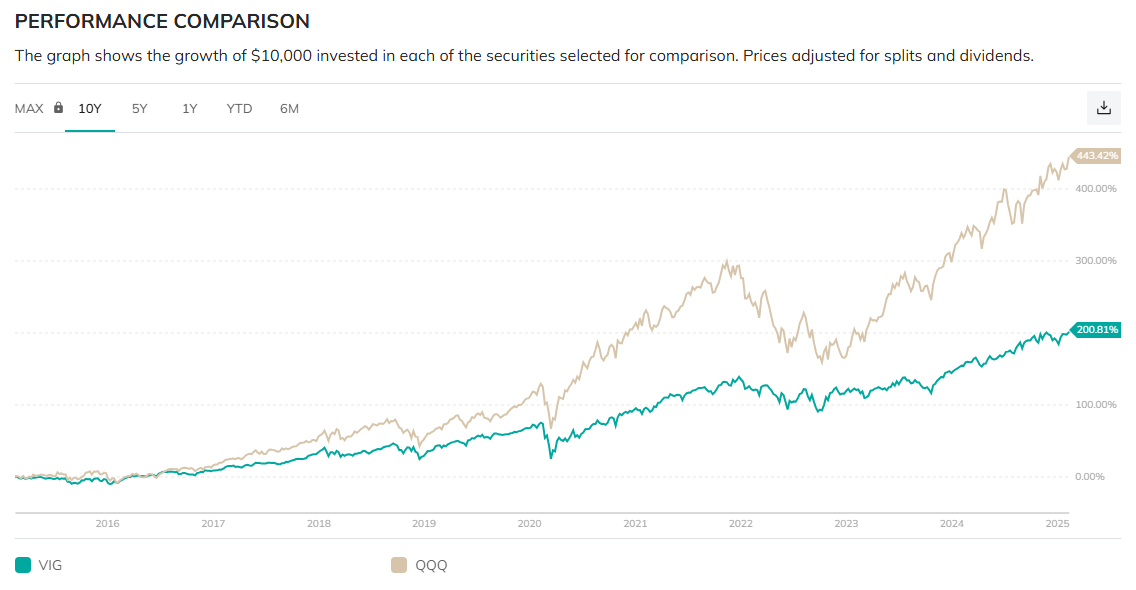
雖然我買了一些優先股 (特別股) 的 ETF, 不過我並不需要了解優先股約定的細節, 只要知道它不會倒, 會配息就好了. 不過其實裡面還是有一點學問, 值得做個筆記.
- Senior/Junior(優先級別)
- 這是關於清算優先權的順序
- 決定在公司清算或出售時,誰先獲得資金返還
- Senior 比 Junior 具有更高的優先權
- Participating/Non-participating(參與權)
- 這是關於額外收益分配的權利
- 決定在獲得優先清算金額後,是否還可以繼續參與剩餘資產的分配
這兩個觀念可以排列組合出 4 種股權.
- Senior Participating(優先參與式)
- Senior Non-participating(優先非參與式)
- Junior Participating(次級參與式)
- Junior Non-participating(次級非參與式)
假如公司遭到清算, 還可以約定優先權倍數 (preference multiple), 例如:1X 表示獲得原始投資金額, 2X 表示獲得兩倍於原始投資金額. 分配的方式當然又和參與式有關:
- 參與式(Participating):
- 先獲得優先權金額
- 然後按持股比例參與剩餘資產分配
- 非參與式(Non-participating):
- 只能選擇優先權金額
- 或按普通股比例參與分配(取較高者)
舉例說明
假設某投資者投資 $100萬,持有 20% 股份,有 1.5X 優先權:
情境 A:公司以 $300萬賣出
- 參與式:
- 先獲得 $150萬(1.5X 優先權)
- 剩餘 $150萬 中再獲得 20%($30萬)
- 總計獲得 $180萬
- 非參與式:
- 可選擇 $150萬(優先權金額)
- 或 $60萬(20% 的 $300萬)
- 會選擇較高的 $150萬
當然, 公司沒倒的話. 優先股可以領取約定的利率, 例如 9%. 那就是 100 萬 * 9%, 每年都可以領 9 萬回來. 假設公司虧損, 又可以約定欠到下一次一起發 (累積), 或是跳過不發. 但只要優先股不發錢, 普通股就不能發錢.
另外, 公司也可以選擇召回優先股. 以目前利率走高的狀態, 要借新還舊相當困難就是了.
案例設定
假設 ABC 公司有:
- 舊優先股:
- 發行總額:$1000萬
- 年股息率:8%
- 每年股息支出:$80萬
再融資方案
ABC 公司決定在當前低利率環境下:
- 發行新優先股:
- 發行總額:$1000萬
- 年股息率:5%
- 每年股息支出:$50萬
- 用新籌得的資金贖回舊優先股:
- 可能需支付贖回溢價(例如面值的 102%)
- 贖回金額:$1020萬(假設 2% 贖回溢價)
財務影響分析
- 年度節省
- 原本股息支出:$80萬/年
- 新的股息支出:$50萬/年
- 每年節省:$30萬
- 成本考量
- 贖回溢價:$20萬(一次性支出)
- 新股發行成本:包括承銷費用、法律費用等
- 假設總交易成本:$30萬
- 投資回收期
- 總初始成本:$50萬($20萬溢價 + $30萬交易成本)
- 年度節省:$30萬
- 回收期:約 1.67 年