先前用過 ChatGPT 3 的人應該都記得這些 Model 動不動就說自己不知道, 不能說, … 但變個花樣問, 不能說的又全說了!
那麼 LLM 怎麼做到自我審查呢? 基本的做法是 RLHF (Reinforcement Learning from Human Feedback) [1], 也就是靠人類的意見來約束 LLM. 但我們不知道 LLM 會被問什麼問題, 總不能一筆一筆叫網路警察來核准吧! 所以我們先根據真人的反饋, 來建立一個獎勵模型 (reward model), 以後就叫 reward model 來代替人工.
當大量的問題, 都有被人類標記為優選的答案, 他們就是一個標準答案 reward model. 它其實也是一個 LLM, 但我們先忘記這件事. 下面講到 LLM 都是指那未經自我審查 / fine tune 的 LLM.
顯然地, 我們拿 LLM 的標準問題 prompt 以及輸出 completion對, 去和 reward model 的標準 prompt + completion 比較, 計算兩者 logits 層 (未經 softmax 之類 activation function 的原始輸出) 的差異, 就知道這個 LLM 回答得像不像人? 然後把 LLM 的 logits 往人類標記的方向調整 [註 A], 就會讓 LLM 的答案愈來愈像人的回答.
我們也可以叫 reward model 標記 LLM 的輸出是否有害? 例如做個 remodel model 專門學 LLM 的輸出是否拉高仇恨值? LLM 答題主要依據 helpful, honest, 和 harmless 三原則. 身為一個機器人, 誠實是基本的. 不能出現言語傷害 (harmless 原則), 也不能因為怕講錯話而淨說沒用的廢話 (helpful 原則) [註 B].
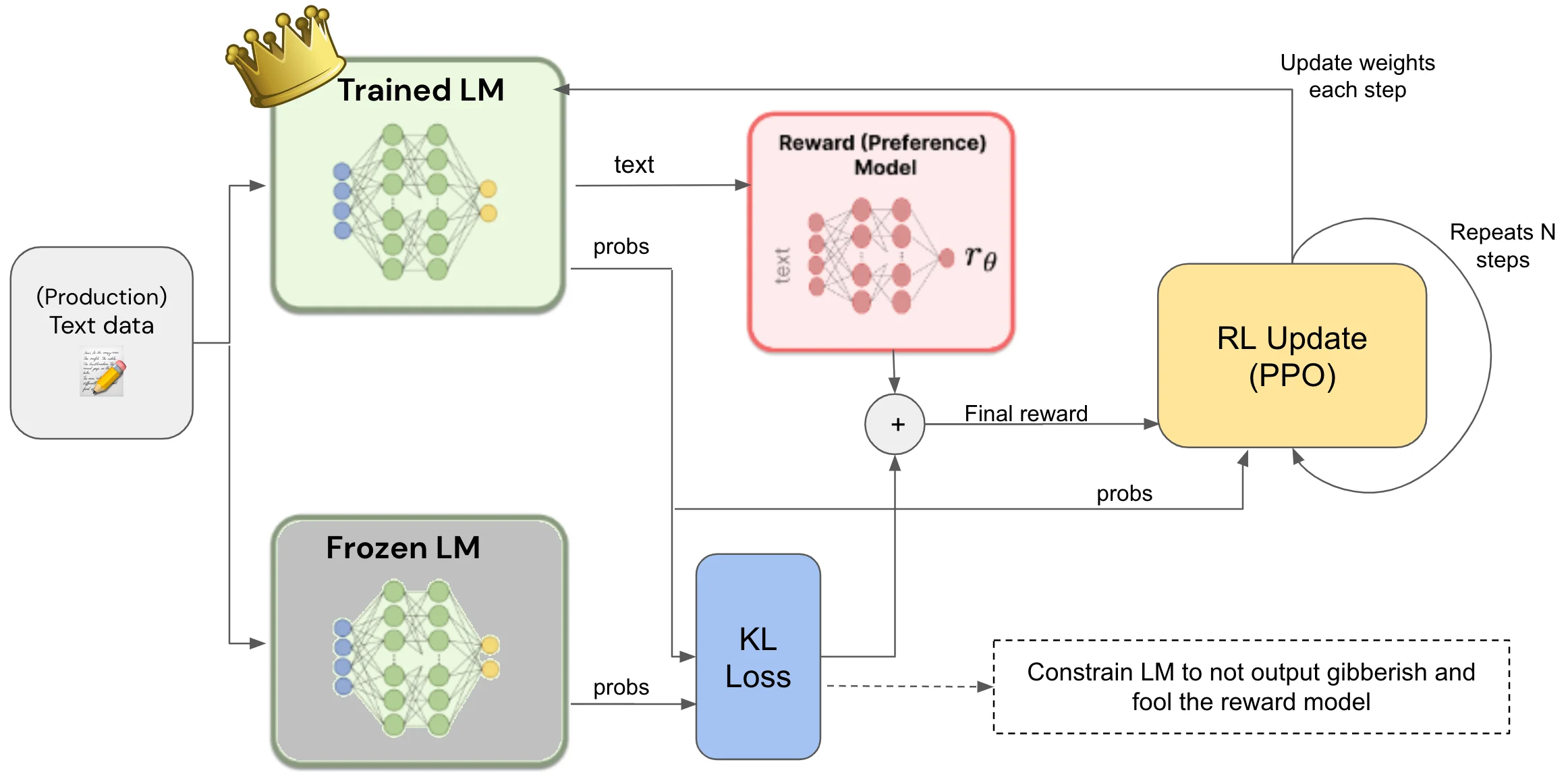
本圖取材自 https://primo.ai/index.php?title=Reinforcement_Learning_(RL)from_Human_Feedback(RLHF
上面的論述略過了好幾段段情節, 在此補充:
[註 A] Reward model 怎麼微調 LLM 參數. 目前常用的一個演算法是 PPO (proximal policy optimization). 我們將它理解為可以調整參數, 但一次不要調太多, 免得把辛苦 train 了半天的 model 調壞. 因此就算要調整, 也是利用 PEFT (Parameter-Efficient Fine-Tuning) 的做法, 包括有名的 Lora.
[註 B] 為避免 Reward model 把 LLM 帶偏, 變成只求不出錯就好, 我們同樣限制調整過的參數和原本的參數 (reference model or frozen model) 不能差太多. 可用的演算法包括 Kullback-Leibler (KL) divergence, 它可以用 softmax 的輸出來比較像不像, 所以根本不用管輸出的 token 是啥以減少計算量. 它可以跟 reward model 共存.
最後, 不免有人會問, 如果一定要有 Human 才能幫 LLM 做思想審查, 是不是太不 AI 了. 沒錯! 其實 Human 也可以換成 AI. 但我們不會叫小學生去教小學生, 我們先叫 LLM 產生一堆負面教材, 然後 train LLM 避免生成這些仇恨、色情、暴力的言論即可. 於是乎, 當我們問 LLM, 不可以上那些色情網站時, 這些剛好都是 RLAIF (Reinforcement Learning from AI Feedback) 的紅隊演練考題, 因此他們侃侃而談, 不知道中計! 當然, 這已經是過去式了~~
[REF]


