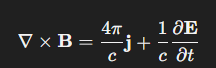61 歲生日前後,剛好是美以伊打得最激烈的階段,害得我才上攻新里程碑才沒幾天,就差點一路跌破去年底的數字。好在不只是我要寫每季回顧、川普投顧也要交季報做帳,所以 3/31 美股收了大漲,算是 “雙贏" (?)。
先講結論,Q1 的投資總值比 25 年年底增加 2.19%,其中美元匯率上漲 2.09%,連日幣匯率都上漲 1.26%。換言之,本人在 Q1 其實毫無長進,說是 “一季回到解放前" 也不為過。那麼我在這一季做了什麼 “虛功" 呢?
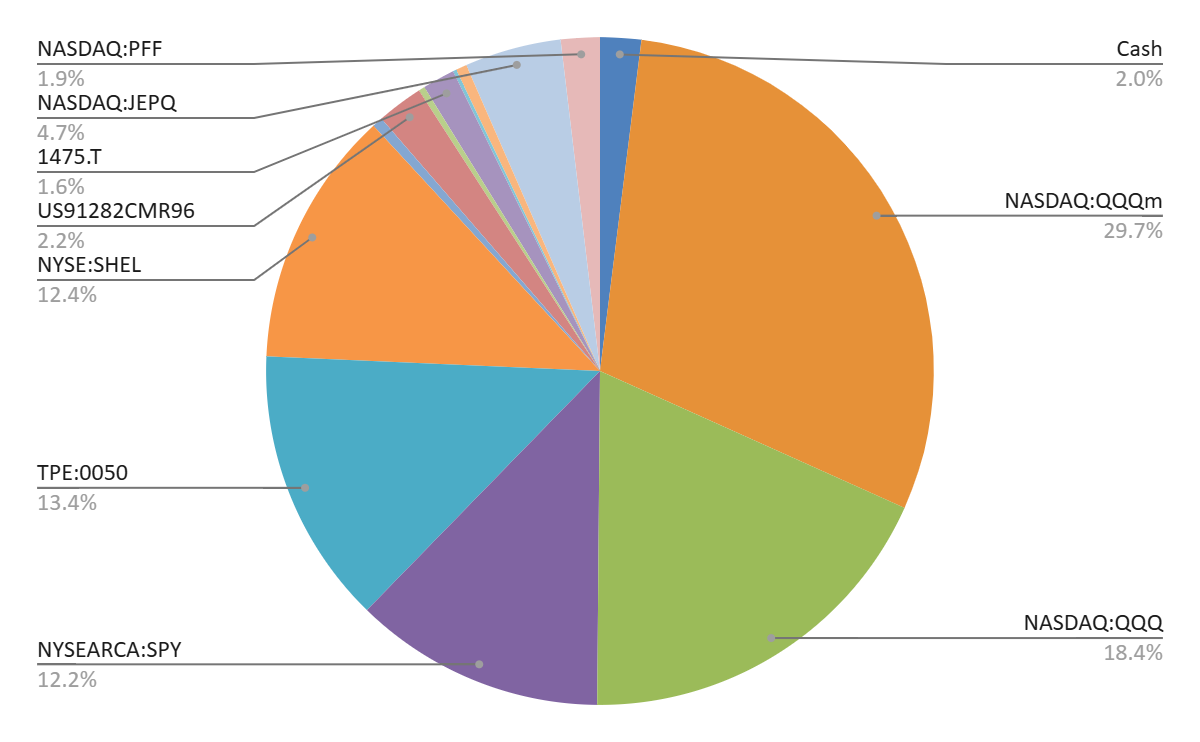
最大的改變是我把部分 QQQ 換成了 QQQm。這兩家的投資標的都一樣是納斯達克 100 指數,只是 QQQm 作為後起之秀 (2020 年 vs 1999 年),管理費用 0.15% 比 QQQ 的 0.2% 低了一點,對長期投資人更為友善。然而,這個換手的動作只能在 Firstrade 做,因為它不收交易手續費,也不需要匯回台灣變成海外所得,只要當沖就可以了。趁著股價下跌,先賣後買就變得容易,中間甚至能賺一點點。
第二個改變是賣出部分 PFF。我不知道和市場缺錢、私募基金最近限制贖回是否有關 [1],總之先記錄一下。在 PFF 最近 3 次的配息中,1 月和 3 月的配息特別低,從大約 0.17 降到 0.065 和 0.031,這對追求收益來源穩定的我有點難以接受。因此我把部分 PFF 賣掉,轉到觀望一段時間的 JEPQ,以確保所得替代率。如果 4 月配息還是不好,那就只好出清了。
- 全名:JPMorgan Nasdaq Equity Premium Income ETF
- 代號:JEPQ
- 發行公司:J.P. Morgan(摩根大通)
- 上市時間:2022 年
- 追蹤標的性質:偏重 Nasdaq 成長股 + 選擇權覆蓋收入策略
JEPQ 主要投資成長股,但是也對 Nasdaq 相關指數或 ETF 賣出買權 (Covered Calls),所以也能配息。缺點是 QQQ 大漲的話,因為上漲利益已經先賣掉了,就享受不到大漲的好處。考慮到 Nasdaq 100 已經佔我資產的一半了,把美好的未來讓利給別人,預先拿現金也是可以接受的。
改變二:同樣是考慮到 Nasdaq 100 (QQQ / QQQm) 和 S&P 500 (SPY) 佔比太大,所以我新開啟 VXUS 的定期定額投資,多投資一點歐洲和日本、甚至是中國。由於這才剛剛開始,它和其他幾筆微小投資一樣小到在圓餅圖沒標籤。
- 全名:Vanguard Total International Stock ETF
- 代號:VXUS
- 發行公司:Vanguard(先鋒)
- 類型:國際股票型 ETF(不含美股)
- 指數性質:被動式,追蹤
- FTSE Global All Cap ex US Index
- 意思是:全球股票,扣掉美國
第三個改變是,按照原定計畫,在可口可樂 (KO) 年初創新高時,我把它賣光了。其他持股基本上都是維持 buy and hold。美以伊戰爭導致 QQQ 下跌一成我沒跑、SHEL 大漲 26% 我也沒加碼。因為我並不追求最大利益,只希望投資標的有未來性、並且配息能夠提供我比較舒適的日常生活開銷。至於為何我沒有抄底 QQQ?主要是我的錢都在上述轉換中用光了,只留下保底、繳稅和換車的錢 ,我可不想舊車再戰 10 年啊 ^^
底下附上圓餅圖,沒有標籤的分別是另外一隻美債、SGOV (0~3 個月美債)、VXUS、敝螃蟹公司半買半相送、乾脆湊一湊的 2379。
[REF]
- 2026年初私募信貸市場因流動性緊張爆發限制贖回潮。貝萊德、阿波羅(Apollo)、黑石等巨頭因投資人申請贖回量超標,限制季度贖回額在5%左右,此舉旨在避免賤賣資產,但引發對私募信貸透明度與風險的擔憂,被喻為「金融完美風暴」前兆。