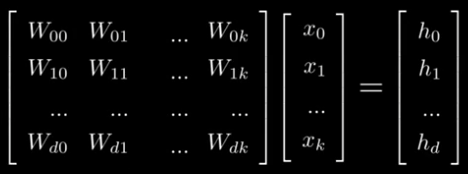基本上這個轉換有兩大類方法, 一類是用官方 tool 去轉, 另一類就是寫個 Python 小程式去做. 原先我都是嘗試後面這路, 但要顧慮的東西很多, 一下修語法, 一下 memory 爆掉, 而是默默出錯時也會轉出 model, 要測試過才知道它的智力有沒有受損?搞得滿累的.
當我再次卡在下面這個檔案限制時, 我就決定換方法了 (悔不當初).
RuntimeError: The serialized model is larger than the 2GiB limit imposed by the protobuf library. Therefore the output file must be a file path, so that the ONNX external data can be written to the same directory. Please specify the output file name.
官方做法其實很簡單, 唯一要顧慮的是 onnx, onnxruntime, onnxruntime_genai 這三個軟體有沒有跟系統衝突? 有沒有跟 NPU tool 衝突 ? 這些搞定就可以了. 用 CPU 也不會轉太久. 這次的障礙是 DeepSeek 跟我講錯指令, 下面這行跑起來找不到 builder.
python -m onnxruntime_genai.builder --model microsoft/phi-2 --precision fp16我去 onnxruntime 安裝的目錄下找, 確實也沒有對應的程式, 所以我把 Monica 預設的 DeepSeek R1 切到提供第二個意見的 Claude Sonnet V3.7, 它就指出 DeepSeek 的錯誤了, 哈!正確指令如下:
python -m onnxruntime_genai.models.builder \
--model microsoft/phi-2 \
--precision fp32 \
--output ./phi-2-onnx \
--execution_provider cpu \
--cache_dir ~/.cache/huggingface \
--extra_options trust_remote_code=True轉完之後, 當然要測試一下有沒有問題? 如果發現它答非所問, 應該就是轉錯了. 然而, 我發現 DeepSeek R1 寫的測試程式還是遜了一點, 所以我又讓 Claude 重寫一次.
import numpy as np
import onnxruntime as ort
from transformers import AutoTokenizer
from typing import List, Dict, Optional, Tuple
import time
class Phi2ONNXGenerator:
def __init__(self, model_path: str, tokenizer_path: str = "microsoft/phi-2"):
"""初始化 Phi-2 ONNX 生成器"""
# 載入分詞器
self.tokenizer = AutoTokenizer.from_pretrained(tokenizer_path)
self.tokenizer.pad_token = self.tokenizer.eos_token
# 設定 ONNX 執行選項以優化效能
sess_options = ort.SessionOptions()
sess_options.graph_optimization_level = ort.GraphOptimizationLevel.ORT_ENABLE_ALL
sess_options.intra_op_num_threads = 4 # 調整為您的 CPU 核心數
sess_options.execution_mode = ort.ExecutionMode.ORT_SEQUENTIAL
# 建立推理會話
self.session = ort.InferenceSession(
model_path,
sess_options=sess_options,
providers=['CPUExecutionProvider']
)
# 獲取模型輸入輸出資訊
self.input_names = [input.name for input in self.session.get_inputs()]
self.output_names = [output.name for output in self.session.get_outputs()]
# 模型常數
self.num_layers = 32 # Phi-2 有 32 層注意力層
self.head_dim = 80 # 每個注意力頭的維度
self.num_heads = 32 # 注意力頭數量
# 快取字首
self.key_prefix = 'past_key_values.'
self.key_suffix = '.key'
self.value_suffix = '.value'
def _initialize_kv_cache(self, batch_size: int = 1) -> Dict[str, np.ndarray]:
"""初始化 KV 快取為零張量,使用預分配記憶體"""
kv_cache = {}
for i in range(self.num_layers):
k_name = f'{self.key_prefix}{i}{self.key_suffix}'
v_name = f'{self.key_prefix}{i}{self.value_suffix}'
# 預分配零張量
kv_cache[k_name] = np.zeros(
(batch_size, self.num_heads, 0, self.head_dim), dtype=np.float32
)
kv_cache[v_name] = np.zeros(
(batch_size, self.num_heads, 0, self.head_dim), dtype=np.float32
)
return kv_cache
def _prepare_inputs(self,
input_ids: np.ndarray,
attention_mask: np.ndarray,
kv_cache: Optional[Dict[str, np.ndarray]] = None) -> Dict[str, np.ndarray]:
"""準備模型輸入"""
inputs = {
'input_ids': input_ids,
'attention_mask': attention_mask
}
# 加入 KV 快取(如果提供)
if kv_cache:
inputs.update(kv_cache)
return inputs
def _update_kv_cache(self, outputs, start_idx: int = 1) -> Dict[str, np.ndarray]:
"""從模型輸出更新 KV 快取"""
kv_cache = {}
for i in range(self.num_layers):
k_idx = start_idx + 2*i
v_idx = start_idx + 2*i + 1
k_name = f'{self.key_prefix}{i}{self.key_suffix}'
v_name = f'{self.key_prefix}{i}{self.value_suffix}'
kv_cache[k_name] = outputs[k_idx]
kv_cache[v_name] = outputs[v_idx]
return kv_cache
def generate(self,
prompt: str,
max_new_tokens: int = 100,
temperature: float = 1.0,
top_k: int = 50,
top_p: float = 0.9,
do_sample: bool = True) -> str:
"""生成文本"""
start_time = time.time()
# 編碼輸入文本
encoded_input = self.tokenizer(prompt, return_tensors="np")
input_ids = encoded_input['input_ids'].astype(np.int64)
attention_mask = encoded_input['attention_mask'].astype(np.int64)
# 初始化 KV 快取
kv_cache = self._initialize_kv_cache()
# 初始化輸入
onnx_inputs = self._prepare_inputs(input_ids, attention_mask, kv_cache)
# 保存原始提示的 token IDs
prompt_ids = input_ids[0].tolist()
generated_ids = []
# 逐步生成文本
for i in range(max_new_tokens):
# 執行推理
outputs = self.session.run(None, onnx_inputs)
# 獲取 logits
logits = outputs[0][:, -1, :] # [batch, vocab_size]
# 應用溫度
if temperature > 0:
logits = logits / temperature
# 選擇下一個 token
if do_sample:
# Top-K 過濾
if top_k > 0:
indices_to_remove = logits < np.partition(logits, -top_k, axis=-1)[..., -top_k:][..., :1]
logits[indices_to_remove] = -float('Inf')
# Top-p (nucleus) 採樣
if top_p < 1.0:
sorted_logits = np.sort(logits, axis=-1)[:, ::-1]
cumulative_probs = np.cumsum(np.exp(sorted_logits) / np.sum(np.exp(sorted_logits), axis=-1, keepdims=True), axis=-1)
sorted_indices_to_remove = cumulative_probs > top_p
sorted_indices_to_remove[:, 1:] = sorted_indices_to_remove[:, :-1].copy()
sorted_indices_to_remove[:, 0] = False
# 將索引轉換回原始順序
indices_to_remove = np.zeros_like(logits, dtype=bool)
for batch_idx in range(logits.shape[0]):
indices_to_remove[batch_idx, np.argsort(-logits[batch_idx])[sorted_indices_to_remove[batch_idx]]] = True
logits[indices_to_remove] = -float('Inf')
# 計算概率並採樣
probs = np.exp(logits) / np.sum(np.exp(logits), axis=-1, keepdims=True)
next_token = np.random.choice(probs.shape[-1], p=probs[0])
else:
# 貪婪解碼
next_token = np.argmax(logits, axis=-1)[0]
# 終止條件
if next_token == self.tokenizer.eos_token_id:
break
# 更新生成的 token 列表
generated_ids.append(int(next_token))
# 更新輸入
onnx_inputs['input_ids'] = np.array([[next_token]], dtype=np.int64)
# 更新注意力遮罩
new_attention_mask = np.ones((1, attention_mask.shape[1] + 1), dtype=np.int64)
new_attention_mask[0, :attention_mask.shape[1]] = attention_mask[0]
attention_mask = new_attention_mask
onnx_inputs['attention_mask'] = attention_mask
# 更新 KV 快取
kv_cache = self._update_kv_cache(outputs)
onnx_inputs.update(kv_cache)
# 計算生成時間
generation_time = time.time() - start_time
tokens_per_second = len(generated_ids) / generation_time if generation_time > 0 else 0
# 解碼並返回生成的文本
result = self.tokenizer.decode(generated_ids, skip_special_tokens=True)
print(f"生成了 {len(generated_ids)} 個 tokens,耗時 {generation_time:.2f} 秒 ({tokens_per_second:.2f} tokens/秒)")
return result
# 使用範例
if __name__ == "__main__":
# 初始化生成器
generator = Phi2ONNXGenerator(
model_path='./phi-2-onnx/model.onnx',
tokenizer_path="microsoft/phi-2"
)
# 生成文本
prompt = "find all prime numbers below 120"
result = generator.generate(
prompt=prompt,
max_new_tokens=200,
temperature=0.7,
top_p=0.9,
do_sample=True
)
print(f"\n提示:\n{prompt}")
print(f"\n生成結果:\n{result}")
DeepSeek R1 給的 inference 程式會寫出大致正確但有錯誤的程式 – 邏輯正確, 但引用函數未定義. 我以為 PHI-2 的極限就是這樣了. 想不到 Claude inference 程式寫得好, 答案竟然也跟著好很多 (雖然還有錯)! 在同樣的 model 下也會有顯著的差異, 令我太意外了.
Claude V3.7 Inference 產生的答案:
import numpy as np
def find_primes(n):
primes = np.arange(2, n)
for i in range(2, int(np.sqrt(n))+1):
primes = primes[primes%i!= 0]
return primes
print(find_primes(120))
DeepSeek-R1 Inference 產生的答案:
import numpy as np
# Define the upper limit
upper_limit = 120
# Create an array of numbers from 2 to the upper limit
numbers = np.arange(2, upper_limit)
# Use the isprime function to find all prime numbers
primes = numbers[np.vectorize(isprime)(numbers)]
print(primes)