Quadrant 是 Aurora 公司推出的軟體, 功能是測量 Android 系統的效能. 相較於 Windows 有官方的性能評分工具, 但是分數的間距很小; Quadrant 比較像是 3D Mark 那樣, 能夠給出比較拉得開的分數. 除了總分, 也可以對 CPU, Memory, IO, 2D 和 3D 做出評價 (Advanced 以上的版本).
假如不用 Quadrant, 有沒有其它的代替方案呢? 有, 前三名還包括 Linpack 和 Neocore. 據說 CF-Bench 也可以測多核心 Android 系統的效能, 差別在於它不測 GPU.
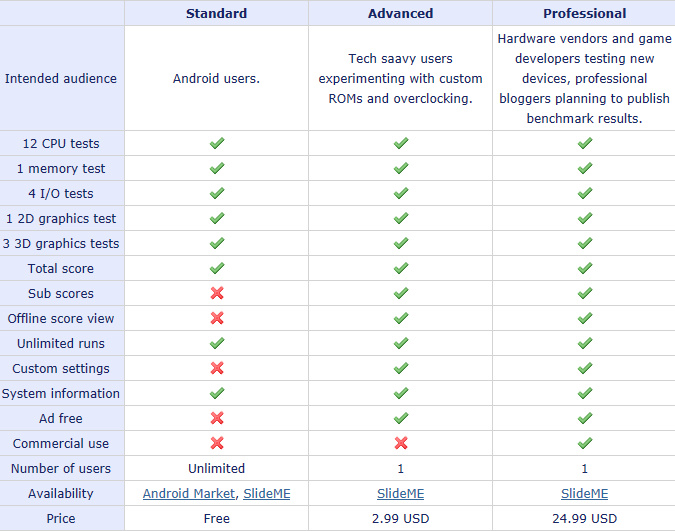
只要用 Google 圖片去 search quadrant, 就可以看到很多 “第一名" 自拍. 我看到最厲害的是 3278 分. 客官啊, 這個 bench mark 的 bench mark 是 1 千多分, 破 3000 分是怎麼來的呢? 原來是有人破解了 Qudrant 的計分標準. 它的罩門在於 IO 速度這一項.
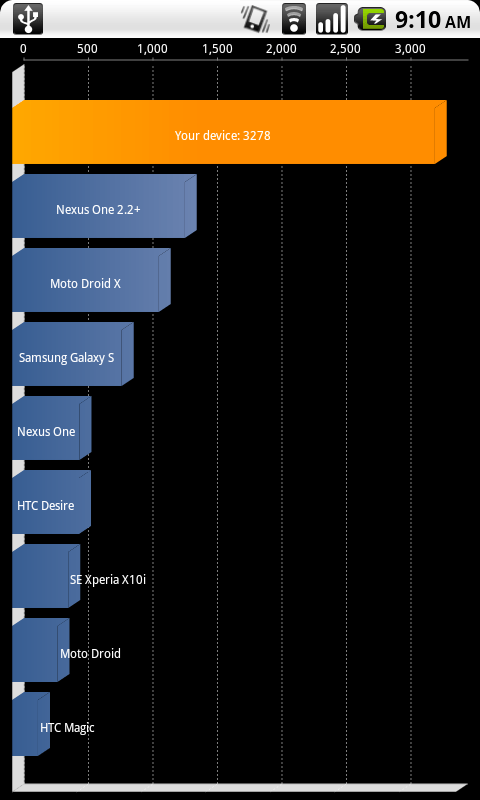
這位 Cyanogen 老兄發現, 只要把 Qadrant 測試用的目錄, 設在用 memory 模擬的 file system 下面, 就可以靠著 IO 方面的優勢, 獲得不可思議的高分. 引用 WIKI 的說明, 下面原文中提到的 tmpfs, 就是用 mount -t tmpfs -o size=1G, nr_inodes=10k, mode=0700 tmpfs /space 之類的指令, 把 1GB 的記憶體, 指定給 space 這個目錄夾使用. Quadrant 拿這個資料夾去測 IO, 當然就不察而給予過度高估的評價.
In Cyanogen’s tweet, he says he was able to exploit the flaw to get obscenely high Quadrant benchmark scores by mounting “a tmpfs over quadrant’s data directory.” A tmpfs, or temporary file storage system, can artificially inflate a device’s I/O score and provide unreal benchmark improvements.
這篇文章的原作者提到, 既然 Qadrant 有 bug, 所以參考意義不大. 不過我想到如果各家廠商要 PK Qadrant 的時候, 說不定也可以用這個技巧來欺騙對手…哈!
[ref] http://briefmobile.com/cyanogen-demonstrates-quadrants-flaws