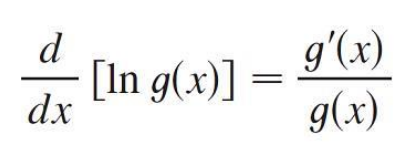美國國庫券 (Treasury Bills, T-Bills) 價錢怎麼算呢? 其實很簡單, 但是要計算天數. 我本來想把這個惱人的事情給 AI 做, 想不到最近數學大有進步的 AI 竟然就瘋了?

[ 3 + 31 + 30 + 31 + 30 + 31 + 31 + 28 + 30 = 3 + 31 + 30 + 31 + 30 + 31 + 31 + 28 + 30 = 3 + 31 + 30 + 31 + 30 + 31 + 31 + 28 + 30 = 3 + 31 + 30 + 31 + 30 + 31 + 31 + 28 + 30 = 3 + 31 + 30 + 31 + 30 + 31 + 31 + 28 + 30 = 3 + 31 + 30 + 31 + 30 + 31 + 31 + 28 + 30 = 3 + 31 + 30 + 31 + 30 + 31 + 31 + 28 + 30 = 3 + 31 + 30 + 31 + 30 + 31 + 31 + 28 + 30 = 3 + 31 + 30 + 31 + 30 + 31 + 31 + 28 + 30 = 3 + 31 + 30 + 31 + 30 + 31 + 31 + 28 + 30 = 3 + 31 + 30 + 31 + 30 + 31 + 31 + 28 + 30 = 3 + 31 + 30 + 31 + 30 + 31 + 31 + 28 + 30 = 3 + 31 + 30 + 31 + 30 + 31 + 31 + 28 + 30 = 3 + 31 + 30 + 31 +…. 後面塞爆自動停了.
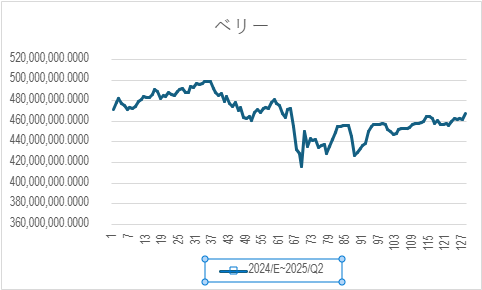
我只好自己把上面加起來, 以利息來算, 經過 244 天.
Bo = FaceVelue * (1 – d * D / 360), 其中
FaceValue = 面值
d= 折扣率 = discount quote (%),
D = 到期日 = day to mature (貨幣市場都小於一年)
360 = 約定俗成的一年天數
Bo = 隱含價格
Discount quote 是什麼呢? 根據報價網站 [1],我們可以看到 US Treasury Quotes 的數據. 記得要選到 Treasure Bills (下圖紅色畫底線), 另外一邊是 Treasury Notes.
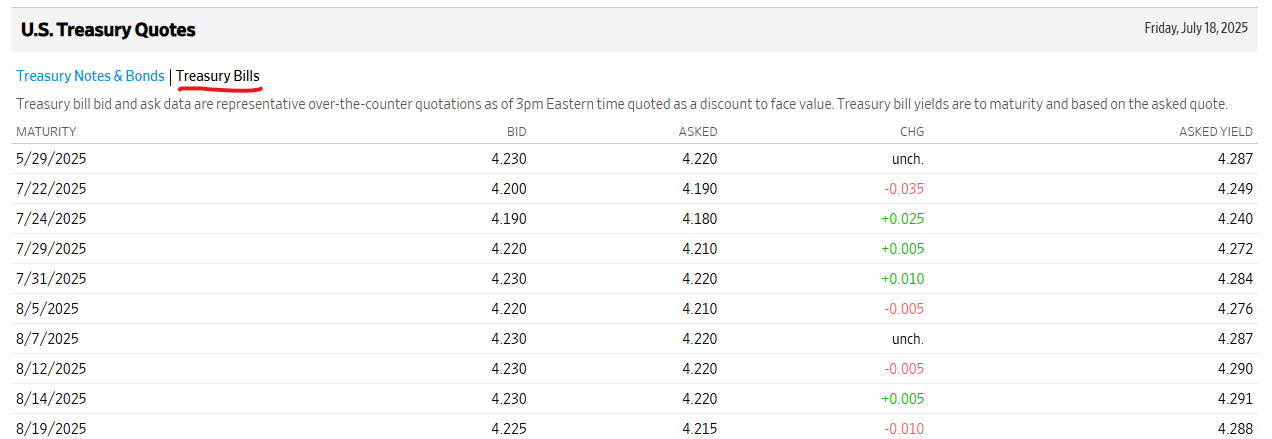
其中, bid (買價) 和 asked (賣價) 都是 discount quote. 所以會算出兩個隱含價值. 在網路課程中, 舉的 discount 都是 0.4%, 過了七八年, discount 已經變成 4% 了!
利率變高好像沒有什麼大不了的, 債券利率也很明顯比以前變高啊! But, 債券是有債息的, 國庫券根本不配息, 它只有面值. 只會透過低於面值的折扣價來買賣.
舉例來說, 美聯儲發行 Treasure Bills 讓銀行買, 銀行用折扣價買入, 準備賺個年利率 5%. 當銀行現金不足, 可以把 T-Bills 賣給別的銀行周轉. 這個流動性是債券所沒有的, 因為它一年之內就會到期, 等同自帶 timer 的現金.
若是經濟不好的時候, 美國不用發現金、不用發 5 倍劵, 而是加價買回市場上的 T-Bills. 因為銀行就是賺錢機器, 在利益優先的考慮之下, 就自動成了美聯儲的打手, 喔不, 推手. 當銀行變得滿手現金, 自然就會想要用它賺更多錢, 也就間接刺激了市場成長. 當然這是最理想的狀況. 等我學成之後, 應該可以舉出很多歪樓的狀況.
[REF]