我請龍蝦幫我摘要 arxiv 的論文,然後寄給我。但龍蝦說它不會寫信,還想出一堆替代方案 – 這簡直就是不負責任。剛才好不容易教會它,因此我也要趕在記憶揮發前,做個筆記把過程寫下來。
幫龍蝦增加收發 mail 的能力。看攻略應該是在 config 設定就可以了,但我在 Ubuntu 上顯然沒那麼簡單。
[階段 0 – 申請帳號]
首先登出自己的 google account,幫龍蝦申請一個 “個蝦" 帳號。像是 Claw123XYZ@gmail.com.
[階段 1 – 編 gog]
安裝 Go 語言環境 (如果尚未安裝) ,gogcli 需要用 Go 來編譯。在 Ubuntu 上執行:
udo apt update sudo apt install golang
下載並編譯 gogcli 依照您提供的指令,將原始碼抓下來並編譯
git clone https://github.com/steipete/gogcli.git cd gogclimake
然而,此時應該編不過。我裝好龍蝦 2026.3.13 版本時,系統預設 tidy 是 1.23。所以我試著更新 go 到最新的 1.25.8 和 1.26.1,結果都沒用。問了 AI 可以退版,所以我到 gogcli 下面,找到 go.mod. 用 editor (e.g. vi) 手動 hack.
// go 1.25.8go 1.18
重新 make 後, 雖然多跑了一點,還是 build error。 我變成在 1.18、1.23、1.25.8、1.26.1 四個版本中掙扎了。總之,我的解法是來回改,最後確認版本和位置,統一到最新版。
go version // 最後是 1.26.1which go // 把正確的 go 加到 PATH
此時還會看到最後一次error,但是可以用 mod 搞定。
go mod tidymake
產生 gog 之後,才能對 gmail 做 auth。這完全是另外一件工作。
[階段 2 – 申請憑證]
- 前往 Google Cloud Console。
- 登入龍蝦本蝦的 google 帳號。
- 點擊左上角建立一個新專案 (New Project),名稱可自訂。
- 在左側選單進入 「API 和服務」 > 「程式庫」,搜尋 Gmail API 並點擊「啟用 (Enable)」。
- 進入 「API 和服務」 > 「OAuth 同意畫面」,選擇「外部」,隨便填寫必填的應用程式名稱與龍蝦的電子郵件,然後儲存。(其實「內部」根本不能選。)
- 進入 「API 和服務」 > 「憑證」:
- 點擊上方「建立憑證」 > 「OAuth 用戶端 ID」。
- 應用程式類型選擇 「網頁應用程式 」。
- 點擊建立後,從下方的紅色圈起來的地方下載 JSON 檔案。
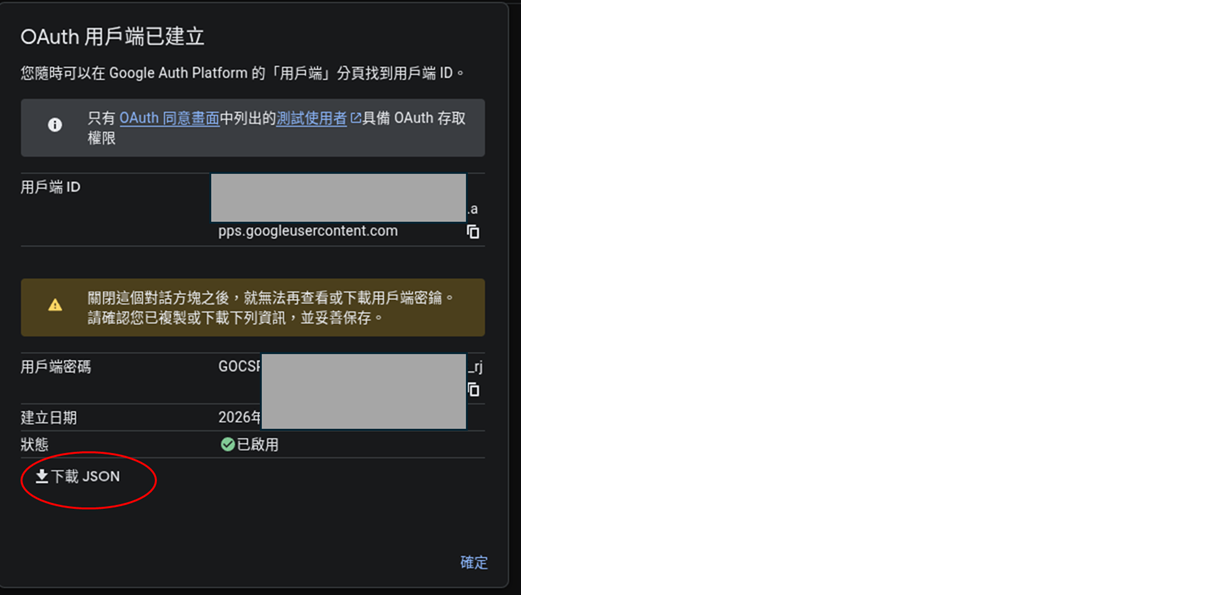
- 將這個名字很長的 JSON 檔案重新命名為
client_secret.json,並移到好保管的目錄下。接著認證這個憑證
gog auth credentials ~/Downloads/client_secret.json
- 對 email 加上這個憑證。
gog auth add Claw123XYZ@gmail.com
- 因為我把 APP 登記為網頁應用程式,所以 auth 的時候,忽然自動開了一個網頁。原來是我忘記先 enable Gmail API,但這時做都還來得及。後續再把這個email 設為預設帳號。
export GOG_ACCOUNT=Claw123XYZ@gmail.com
- 測試信箱是否建立? 看到收件夾這些都在,表示沒問題。
gog gmail labels list
- 發個信給別人
gog gmail send --to="Claw456@gmail.com" --subject="蝦一跳" --body="我是龍蝦。"
收到信了,表示 account 大功告成。