最近想在 Notebook 上建一個 AI 模擬的環境, 其中遇到一些關卡值得記錄下來.
在 Notebook 上建個虛擬機來跑 AI…. 畢竟 Linux 的環境比 Windows 直覺, 所以先做了這件事. Linux 軟體安裝起來相對容易, 重點在權限開對, 路徑設定可以憑直覺.
這樣很快就可以用 CPU 跑 facenet, But, 我是想要用 GPU 來跑啊!? Google 了一下發現虛擬機的 driver 不是 cuda 相容的, 必須要裝雙系統, 有原生的 Ubuntu 才可以跑. 因此又被打回 Windows 10 環境.
在 Windows 10 上面, 當然很直覺要先裝個 Python. 但這不是最佳的選擇. 應該先裝 GPU driver, 然後裝 Anaconda [1]. 原因是 Anaconda 下可以裝很多套不同版本的虛擬 Python 環境, 即使 model 只支持特定 Python 版本, 也不需要重新安裝 Python. 畢竟 Python 2.x 和 Python 3.x 就不相容了, 換來換去很麻煩.
若先裝 Python, 再裝 Anaconda, 後者會問要不要把 Anaconda 設為 Python 的預設程式? 如果選不要, 我發現很多怪現象會發生. 例如 Anaconda Navigator 搞失蹤之類的. 即使把既有的 Python 解除安裝, 在沒有重新開機之前, 純 Python 還是會在背景干擾 Anaconda Python. 所以乾脆反過來只安裝 Anaconda, 把它設為預設程式.
Step 1: 下載並安裝 Anaconda 3. 版本 4 和 5 好像是要錢的企業版.
然後在 Anaconda 底下的 envs 目錄下可以看到多個目錄, 每一個代表一種虛擬的環境. 當然這個要按照 Anaconda 的官網說明去創建, 如果不建立這底下就是空蕩蕩的. 環境做好之後, 會在 Windows 的程式集裡面看到成對的 prompt, Spyder…等等. prompt 就是命令列, Spyder 有 GUI, 而 reset 顧名思義就是把這個虛擬環境清掉重來, 在裝錯軟體的時候很好用.
Step 2. 建立 Anaconda 下的虛擬環境, -n 的後面跟著名字, 例如我用 tensorflow-gpu 就可以來來區隔這個環境是跑 GPU 版本的. 但這只是名字而已, 真正的安裝在後面步驟. 但我後來後悔用這麼長的名字, prompt 變得很長. 此處指定了 python 的版本.
c:> conda create -n tensorflow pip python=3.6
Step 3. 啟用這個環境.
C:> activate tensorflow
(tensorflow)C:> # Your prompt should change
Step 4. 安裝跑 GPU 版本的 tensorflow. 這邊的 tensorflow-gpu 就是關鍵字不能改了.
(tensorflow)C:> pip install --ignore-installed --upgrade tensorflow-gpu
以上 Step 1~4 參考 Anaconda 官網 [1], 還有教人如何驗證安裝正確與否.
此外, tensorflow-gpu 往下需要 Cuda 和 Dnn 的函式庫. 參考這篇 [2] 即可. 其中, Cuda 要用第九版, CuDnn 應該用 V7 或 V7.1. 至於 GTX 顯卡的 driver 是本來就有的, 如果您是用 AMD 系列的顯卡, 這個我就沒研究.
這裡看起來很簡單, 但是陷阱也很多. 如果裝錯的話, 後續跑 tensorflow-gpu 就會報錯, 說找不到 cudart.lib, cudablas.lib….等等. 原因在於大家可能在安裝 GTX 顯卡的時候, 就在 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v9.0\lib\x64 底下安裝了 cuda 相關的函式庫, 所以優先被執行到.
若安裝正確的話, 應該在指定的目錄 (解開 cudnn-9.0-windows10-x64-v7.zip 後手動放的那個目錄), 看到 cudnn64_7.dll. 然後把這個目錄加入 path. 網路上有很多人求救, 他們可能是把 32 bit / 64 bit 搞錯, 或已經安裝了 cudnn-9.1 但 tensorflow 只支援到 9.0 之類的, 總之痛下殺手把電腦的版本降級配合 tensorflow 就行了.
搞定 dnn 之後, 就可以按照滿山遍野的網路教學跑 MTCNN + Facenet [3][4]. 但還是要請大家再次釐清一個觀念是: 既然我已經用 Anaconda 做虛擬環境, 一切都要在虛擬環境下執行. 也就是 envs/tensorflow-gpu (舉例)/ 而不是 Anaconda 目錄下 [3]. 然後呢…facenet 是一個 module, 必須安裝到 lib/site-packages/ 底下才能執行, 光是下載 facenet copy 進去是沒用的.
Python 中安裝 module 的方法有很多種[5]. 我們只需要用到最簡單的 pip install facenet 即可. 其他的按照 [4] 應該就可以依序執行 MTCNN 和 Facenet. 這邊會踩到的雷是: Windows 系統的字型編碼會造成 facenet error, 這個外國人可能遇不到. 大約在 facenet.py 的 577 行左右, 要把原文改為我下面的這行代碼. 當然最前面要記得 import io.
# with open(rev_info_filename, “w") as text_file:
with io.open(rev_info_filename, “w", encoding="utf-8″) as text_file:
然後, 如果要 traning 自己的 database, 還有一行要改. 在 train_softmax.py 的 95 行左右, 無論換哪個 database, 它都固定去讀 data/pairs.txt, 所以我硬改一個寫死的目錄, 以便可以測 mydata.
# pairs = lfw.read_pairs(os.path.expanduser(args.lfw_pairs))
pairs = lfw.read_pairs(os.path.expanduser(‘mydata/pairs.txt’)) #Cash modified
在跑 MTCNN 的時候, 網路上很多文章都說要執行
python ~/tensorflow/facenet/src/align/align_dataset_mtcnn.py ~/tensorflow/lfw/raw ~/tensorflow/lfw/lfw_mtcnnpy_160 –image_size 160 –margin32 –random_order –gpu_memory_fraction 0.25
最後面 –gpu_memory_fraction 0.25 這個參數, 其實是 facenet 官網 [6] 跑四個 process 的關係, 跑 4 個當然每個人用 1/4 (0.25) 囉. 如果只跑一個 process, 加上這行唯一的好處是記憶體比較不會爆掉.
以上是跑 tensorflow 主線任務的紀錄. 支線上任務則是曾經試圖跑 mxnet + opencv 的版本, 結果第一路打通就沒繼續奮鬥了.
Step 1. 下載 opencv V.3.4.1
https://opencv.org/opencv-3-4-1.html 選 https://github.com/opencv/opencv/tree/3.4.1
Step 2. 解開 opencv 發現要 cmake.
Step 3. 下載 Visual Studio Community 2017
Step 4. 在 Visual studio 的 “工具" 裡面選 “擴充功能與更新", 選 cmake 下載, 安裝.
在 “工具" 選 “取得工具與功能", 選 “工具負載" 裡的 “其他工具組" 的 “使用 c++ 進行 Linux 開發", 選 “Web 與雲端" 的 “Python 開發".
Step 5. 下載 cmake, 在 https://cmake.org/download/ 選 cmake-3.12.1-win64-x64.msi
要選產生 GUI 比較方便.
Step 6. 在 Cmake GUI 選 source code 位置, Build binary 位置, 選 Configure, 跑一段時間, 選 Generate 產生 build file. 選 Open Project 帶起 Visual Studio. [7].
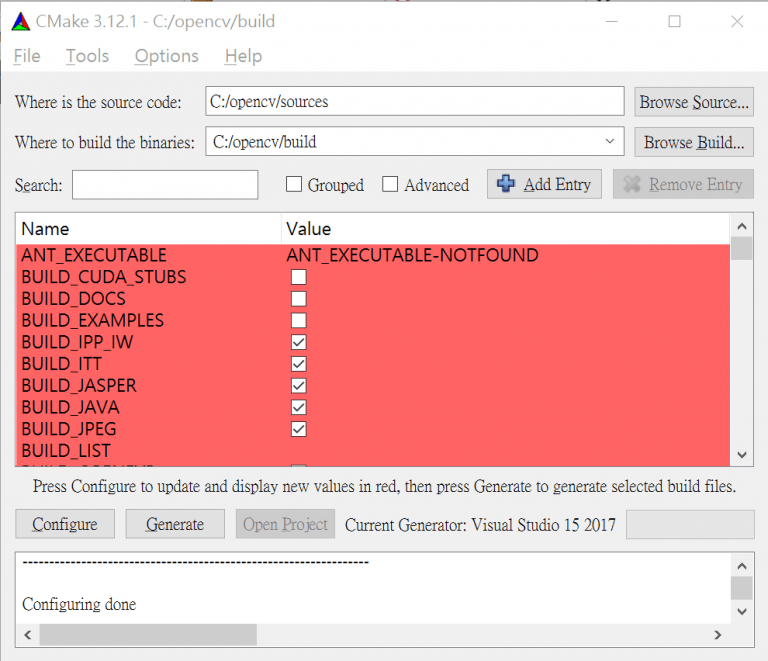
Step 7. 在 Visual Studio build 這個 project. 參考 [8] 作一些修改. 但它的版本比較舊, 在我的平台上要把 VC10 改為 VC15, x86 改為 x64. opencv 改為 opencv 和 opencv2.
Step 8. 編成功後, 會在 c:\opencv\build\release\bin\debug (舉例) 看到一堆檔案, 這樣就成功了. 其中 opencv_interactive-calibrationd 跑起來會自動抓 NB 前鏡頭的畫面, 看了會很有感. 上面截圖時, 我把 binary 位置選在 c:\opencv\build, 但裡面本來就有檔案了, 再放自己編出的檔案會糊成一團, 故第二次我把 target 改到 c:\opencv\build\release.
Step 9. 安裝 mxnet
這個網頁可以自訂要下載哪一種 mxnet 的版本, 相當地人性化. 我選了

https://mxnet.apache.org/install/index.html?platform=Windows&language=Python&processor=GPU
Step 10. 建議安裝 Anacoda — 請參考前面說的.
Step 11. 升級 mxnet 以支援 GPU
pip install mxnet-cu92
Step 12. 調整路徑
不調整路徑的話, 直接 load mxnet 版本的 facenet 會出現找不到 module 的錯誤. 事實上, 採用 Tensor flow 版本的人也是一直再狂問為何找不到 tensorflow module. 這些都是路徑的問題.
正常安裝完的 module 都會放在 pythonxxx 下面的 Lib/site-packages.
[Note]
- https://www.tensorflow.org/install/install_windows
- http://blog.nex3z.com/2017/04/18/%E5%9C%A8-windows-%E5%B9%B3%E5%8F%B0%E5%AE%89%E8%A3%85-nvidia-gpu-%E5%8A%A0%E9%80%9F%E7%9A%84-tensorflow/
- https://blog.csdn.net/xiangxianghehe/article/details/72809600
- https://blog.csdn.net/chzylucky/article/details/79680986
- https://packaging.python.org/tutorials/installing-packages/
- https://github.com/davidsandberg/facenet/wiki/Classifier-training-of-inception-resnet-v1
- http://gclxry.com/use-cmake-on-windows/
- http://monkeycoding.com/?p=516
