睡不著來更新過年期間另一件搞笑的事. 年後上班第一天, 電視說台股補跌. 我出門前特別看了眼 APP, 確認我的 0050 的確跌了不少. 大盤和 0050 兩者當然是連動的, 只是電視頂多報台積電股價, 不會講到0050. 所以我早上真的還有看到股票的身影. 然後我想說如果一路跌下去的話, 中午就來撿便宜. 先去上班吧.
結果開工日也是頗忙, 中午吃完午餐都快一點了. 這時猛然想起要確認股價竟跌到那裡?興沖沖地打開 APP 一看! 诶? 我的股票呢? 怎麼連一股都沒有了! 庫存為 0 !! 難道是我早上不小心按到賣出嗎?還是被手機被駭客入侵啦?但就算被盜賣了也是要先有個成交回報, 然後才能轉帳給駭客啊? 怎麼看來看去都像是憑空消失呢? 害我傻住了一會兒.
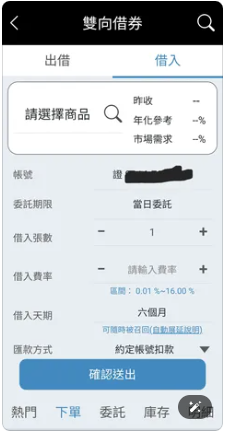
忽然我又靈光一閃 – 其實是窮舉法搜尋完了. 難道是那好幾年都無人問津的股票借券, 終於被借去放空了? 我指尖微抖地在 APP 裡面亂點, 不確定完整的 flow 的是什麼的情況下, 最後在 “雙向借券" 裡面 “借出" 的那一頁, 看到 “賀成交" ! 這讓我鬆了一口氣, 至少知道它們的下落了.
當初會想要借券, 都是受到華倫大的影響. 他總是在臉書曬他的借券收入. 一年能多賺個好幾萬塊. 我想說輸人不輸陣, 我也有股票可以出借啊! 所以我多年前就設定了 3% 利息, 等勇者上鉤 (這是一個 “夢幻西餐廳" 幫菜色定價的概念 [1]). 不料華倫大的股票很多人借, 我的股票就是沒人要. 我只好試試 2% 幾天, 再試試 1% 幾天, 最後賤價 0.3% 都借不出去. 然後我就忘記了….
本圖取材自華倫存股臉書. (facebook.com/teacherwarrenc)
結果就在那個 DeepSeek moment, 很多 0050 成分股都可以用 1% 出借的那一天, 我的 0050 也被借去放空了! 我自己是死忠看多大盤的, 甚至 buy and hold, 當然不可能去放空! 更別說空大盤! 但要是高手技癢想放空, 歡迎多加利用, 大家各取所需, 只是我下次會把利率訂高一點.
畢竟, 認識的跟我借錢的人常常會忘記還、或是懶得還. 還是借給不認識的人比較不會傷感情. 只是這為數不少的 $$$, 雖然有證券公司作莊, 不至於被賴帳. 但我看著庫存空空如也, 也是有點落寞. 打開 APP 又不能幹嘛. 喔, 對了, 前幾天可以參加印能科技和威剛的抽籤啦!
股票借出後, 名字就會登記給別人. 往後股價漲跌、股東會 (紀念品)、配息什麼的就都不甘我的事了. 至於重要的股息, 會由券商把轉給我; 其中二代健保補充費、股利所得都是扣對方的. 我覺得這個對我節稅也有利. 此外, 我還可以隨時召回 – 只是要提早一個月申請.
適逢元大要將 0050 分割, 營業員問我要不要召回以參加投票 [2]. 其實我沒太大意願投票, 畢竟幾張股票又影響不了大局. 但我的確有點想念它們, 所以請營業員順便幫我召回. 於是乎, 這次 0050 放空記, 就以小賺 “收驚費" 告一段落.
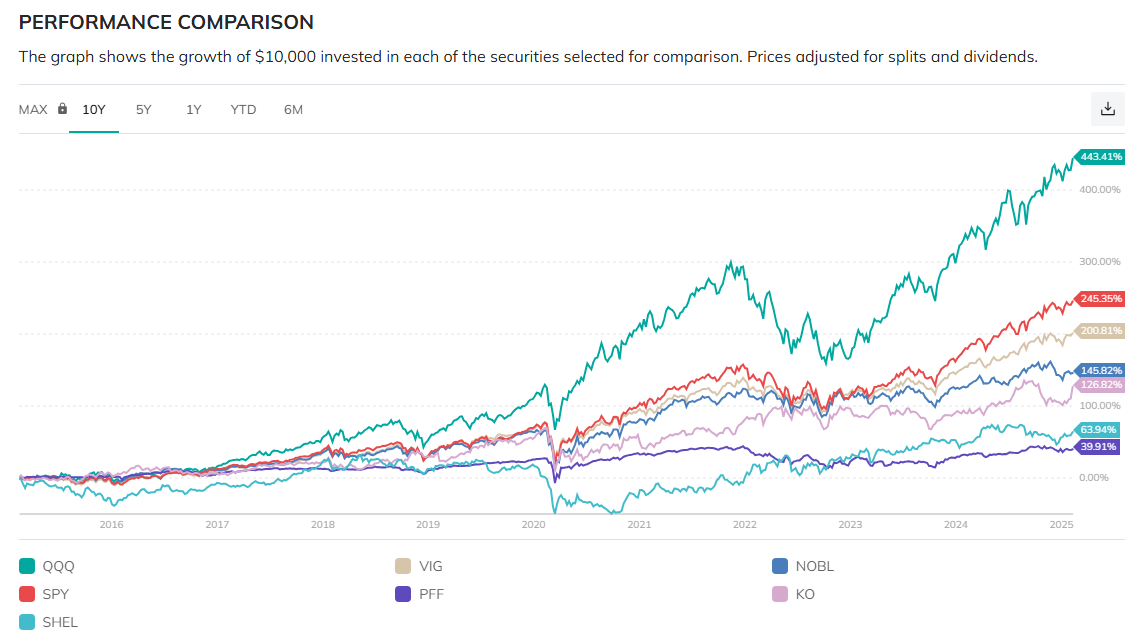
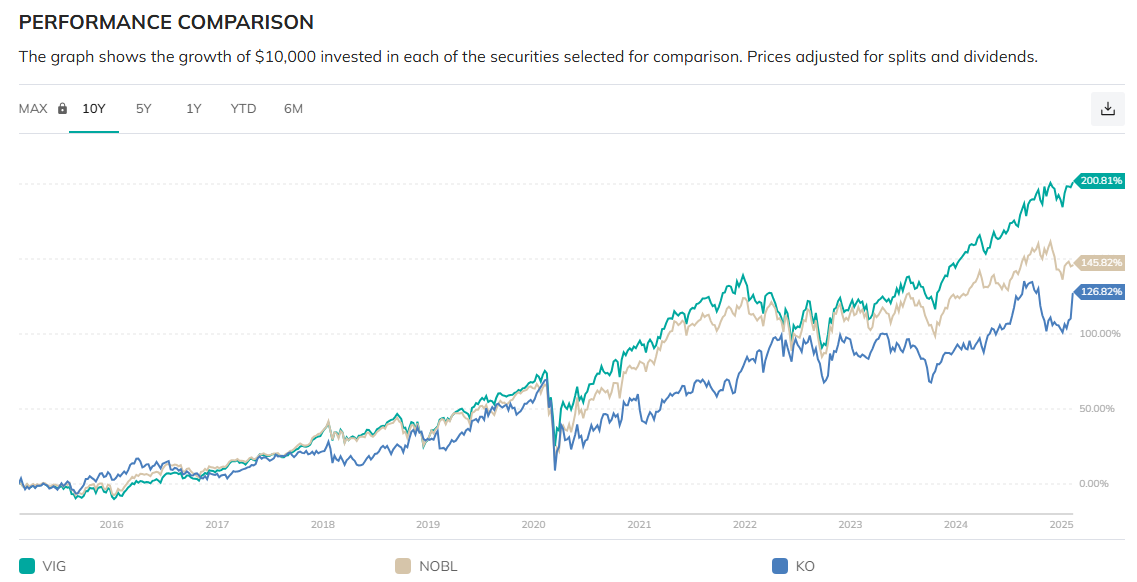
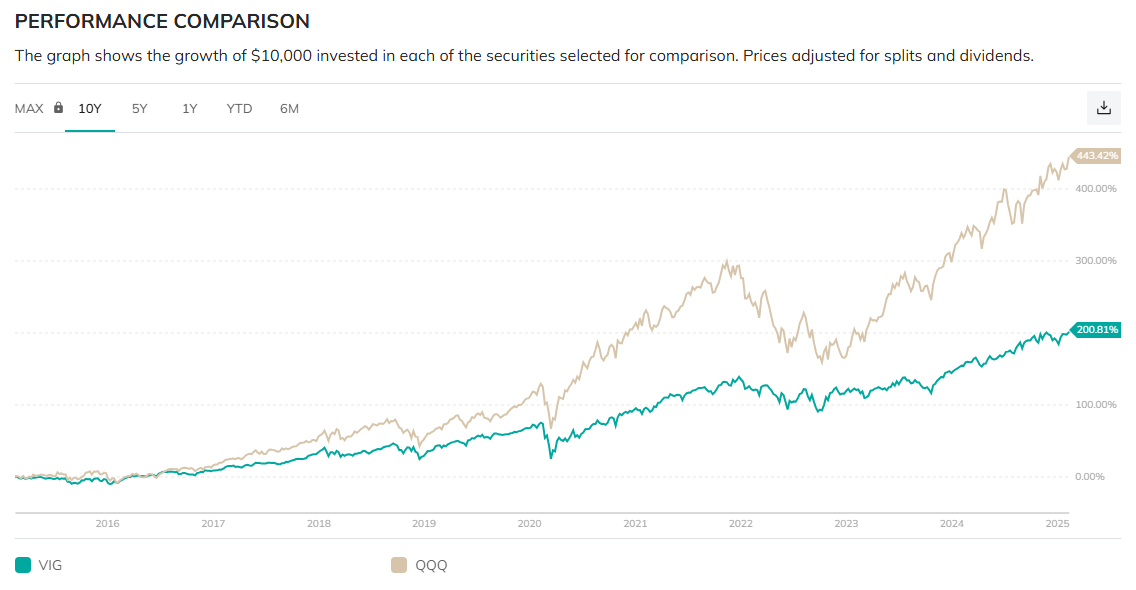
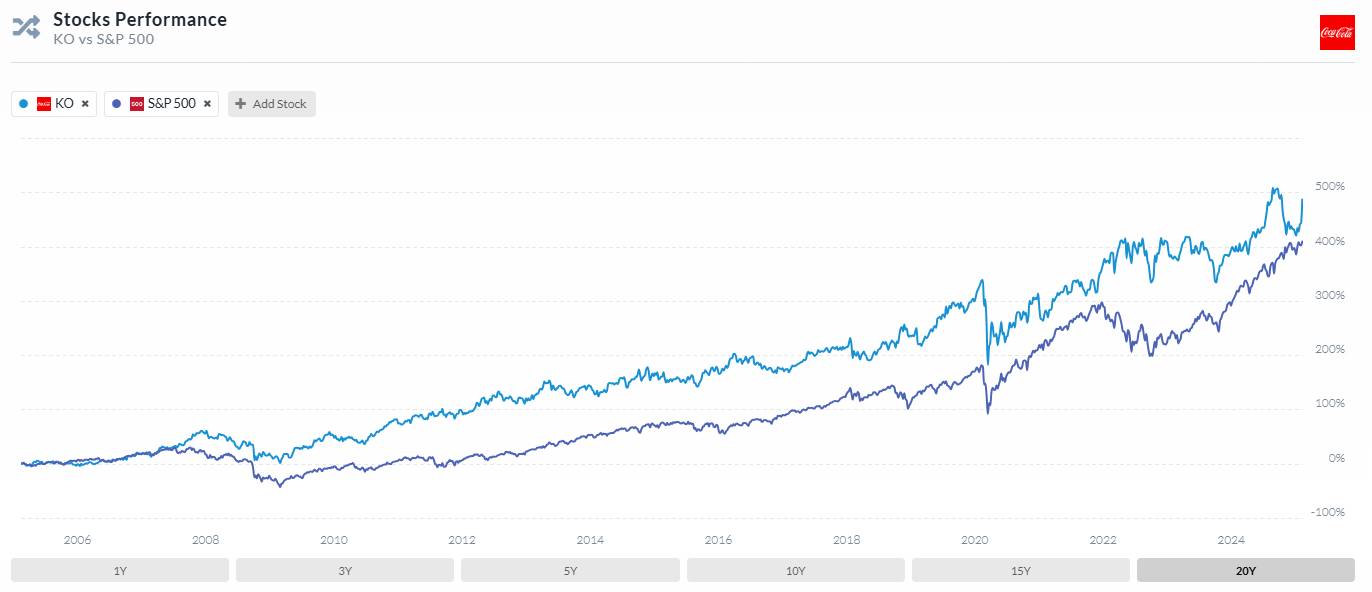
哇! 關機前看到歷史的一刻. QQQ 540.71, SPY 613.1, 我商務艙的錢有人付了….
[REF]