前次提到取樣的比例太低時, 樣本誤差需要做修正. 當時的隨機變數是一個數字, 所以它有平均值的概念. 那麼隨機變數如果是一個比例呢? 例如紅豆在八寶粥當中的比例是多少? 所有的紅豆集合起來才能貢獻出一個隨機變數, 因此就沒辦法算出平均值或標準差了.
此時, 我們假設樣本數 n, 樣本中呈現的比率 p, 樣本誤差 D. 那麼在母體當中的比率, 可以用 p ± D 來表示. 而書上說 D = 1.96 x sqrt (p(1-p)/n).
換言之, 若我們舀了一匙的八寶粥, 裡面全都是紅豆, 或是半顆紅豆都沒有; 則 p(1-p) 肯定是 0, 樣本誤差 D = 0. 這表示我們就得相信我們買到的七寶粥 (少了紅豆), 或是一寶粥 (只有紅豆). Well, 這好像是公式的 bug.
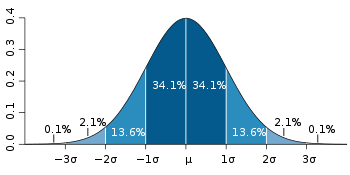
它的理論可以從這裡找到支持. 假設標準差為 µ, 它的平方為變異數 v. 書上說:

換言之, 不要把 p 看做單一的值, 而是一個二值化 (0 or 1) 數列, 一種類型數據, 的平均值的話. (1-p) x p 就像 0 與 1 在對均值 p 計算離均差. 而變異數 v 又是離均方差的平方和的期望值 (平均值). 因此兩者的確很類似.
當然, 上次講到的修正值在比率分析中也是有效的. K = sqrt((N-n)/(N-1), N 表示母體的全部樣本數.
我還漏掉一個東西沒寫, 那就是精確度 (相對誤差), 它等於樣本誤差除以 p (比率) 或是上次的 m (平均值). 個人覺得相對誤差的意義不大, 理論基礎以後再討論.
了解了樣本誤差之後, 當我們再看到政策的支持度由 33%, 降到 27%, 再降到 25% 的時候, 要記得把每個數字都加減樣本誤差, 以得到一個 “母體比率信賴區間".
如果三次民調的信賴區間是重疊的, 那麼我們可以認為三次民調的意義沒有差別. 如果兩次民調和另外一次民調的信賴區間沒有重疊, 那麼它的效力就等於兩次有效的民調. 若三次都沒有重疊, 那麼支持度就真的持續下降了.
以上整理自 “真希望老師這樣教統計".