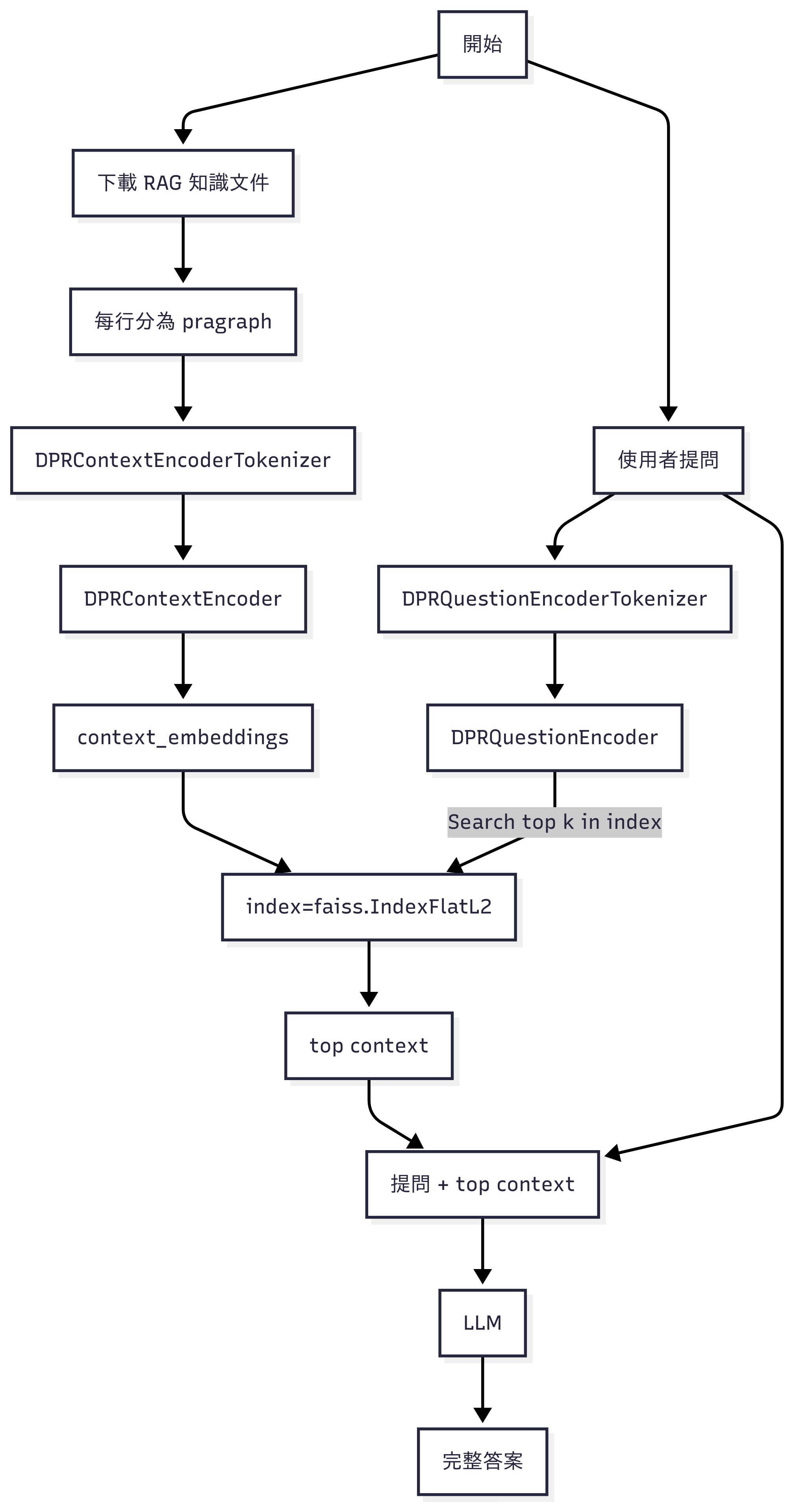
Rag 聽起來就像一塊破布. 但是在 AI 領域還滿紅的! 不同於普通的破布, 這個 RAG 是 Retrieval Augmented Generation 的縮寫. 看 keyword 就知道包括檢索 – 增強 – 生成. 整個功能的目標還是做生成式 (generative) AI.
那麼和普通的 LLM 差在哪裡呢? 普通的 LLM 學習了大量的知識, 但是可能有些專業領域沒學到, 或是還可以加強, 這時候就會用 RAG.
首先我們要把這些 “新知" 進行編碼, 在自然語言處理當中會用到 Embedding 技術, 把普通的文字轉換成向量. 此處我們既然想依賴既有的 LLM model, 當然我們要把我們新知和 LLM 的習知, mapping 到同一個空間去! 此時就用到了增強 ( augmented ) 這部分.
Step 1: 找到 Embedding 模型
from sentence_transformers import SentenceTransformer
encoder = SentenceTransformer('一個 EMBEDDING 模型')
Step 2: 為新知建立向量空間
這裡有個熱身的步驟, 先在 memory 當中產生一個 instance.
from qdrant_client import QdrantClient, models
qdrant = QdrantClient(":memory:")
接下來就可以設定新知的參數, 主要是 size 和 distance.
qdrant.recreate_collection(
collection_name="新知的名稱",
vectors_config=models.VectorParams(
size=encoder.get_sentence_embedding_dimension(),
distance=models.Distance.COSINE
)
)
Step 3: 把新知的內容搬到向量空間.
其中 data 當然就是由 index (idx) 和 doc 組成.
qdrant.upload_records(
collection_name="新知的名稱",
records=[
models.Record(
id=idx,
vector=encoder.encode(doc["新知的內容"]).tolist(),
payload=doc
) for idx, doc in enumerate(data)
]
)
Step 4: 以文字在向量空間檢索 (retrieval) 得分最高的新知.
answer = qdrant.search(
collection_name="新知",
query_vector=encoder.encode("針對新知的問題").tolist(),
limit=1 # 想要前幾高分的回答, 例如 1,3,5
)
for ans in answer:
print(ans.payload, "score:", ans.score)
由於這個新知的 database 知道的東西比較偏門, 它怎麼跟大語言模型共用呢? 答案就是把上述 RAG 的結果當作 LLM 的提示, 這樣 LLM 就會去 RAG 的輸出找答案.
Step 5: RAG 跟 LLM 互助合作
底下是叫 Copilot 寫的範例. 示意 RAG 的結果被 LLAMA2 拿去參考. 實用性不高, 但畢竟整合起來了.
search_results = [ans.payload for ans in answer] # 上面的新知
# Import necessary libraries
import os
import pinecone
from langchain.llms import Replicate
from langchain.vectorstores import Pinecone
from langchain.text_splitter import CharacterTextSplitter
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.chains import ConversationalRetrievalChain
# Set your API keys
os.environ['REPLICATE_API_TOKEN'] = "YOUR_REPLICATE_API_KEY"
pinecone.init(api_key='YOUR_PINECONE_API_KEY', environment='YOUR_PINECONE_ENVIRONMENT')
# Initialize Llama-2 components
replicate = Replicate()
pinecone_store = Pinecone()
text_splitter = CharacterTextSplitter()
embeddings = HuggingFaceEmbeddings()
retrieval_chain = ConversationalRetrievalChain()
# Example query from the user
user_query = "What are the health benefits of red wine?"
# Retrieve relevant information from search_results (assuming it contains relevant data)
relevant_data = search_results # Replace with actual relevant data
# Process the user query
query_vector = embeddings.encode(text_splitter.split(user_query))
# Retrieve relevant responses using the retrieval chain
retrieved_responses = retrieval_chain.retrieve(query_vector, pinecone_store)
# Generate an answer based on the retrieved responses
answer = replicate.generate_answer(user_query, retrieved_responses, relevant_data)
print(f"Chatbot's response: {answer}")
用這個方法, 就不需要重 train 大語言模型, 也不影響 LLM 原本的實力. 但看官一定可以發現, 同一個問題必須分別或是依序丟給 RAG 和 LLM, 此時 RAG 才能產出東西給 LLM 當小抄 (in-context prompting). 這就是它的缺點.
使用 Vector Store 並非唯一的方式, 想要學習 WIKI, database, …. 都是可行的. 只要能把它變成 prompt 就可以改善 LLM 資訊不夠新 (knowledge cut off) 的幻覺 (Hallucination) 問題.