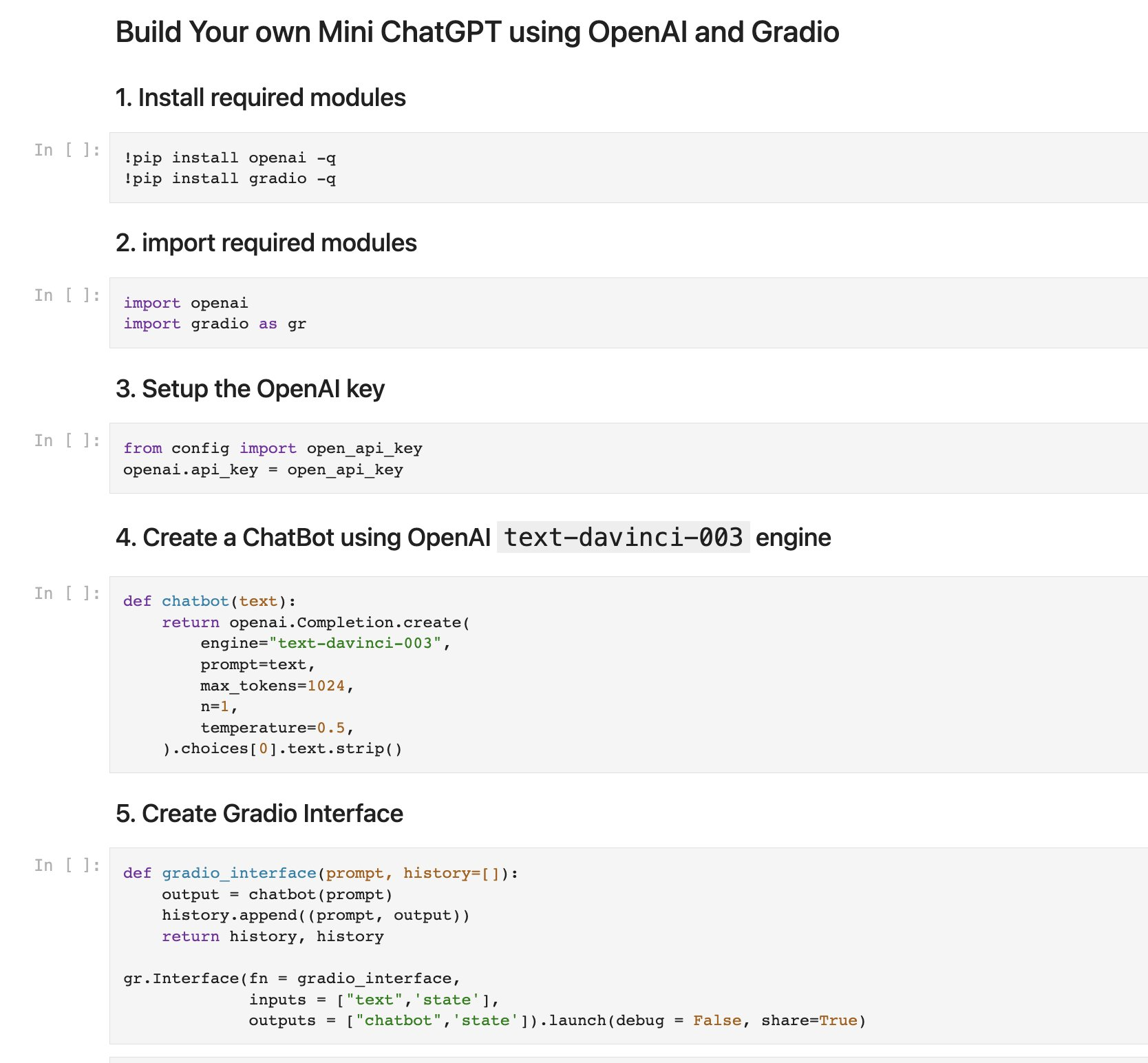
Realtek 公司也簡稱 R, 不過應該沒有多少人用過 R 語言. 最近適逢要用到 regression model, 但網路課程幾乎都是用 R (歷史包袱), 而不是 Python, 所以我也試著瞭解用 R 來理解 regression model.
首先 library(UsingR) 載入基本套件, 然後用 x 來 predict y.
y = β0 + β1 * X
在程式中, 以 beta0 取代 β0 , 而 beta1 取代β 1 , 因為我們只是 predict, 並不是 assign 值給 y, 所以要求的是 minimum square error.
∑i=1n(Yi−(β0+β1Xi))2
為了增加趣味性, 課程舉例是用父母的身高預測小孩的身高. 我們可以理解到身高不會為 0, 所以有一個 beta0 撐著, 然後父母身高 X 乘上的 weighting beta1, 就可以預測小孩的身高. 當然, 我們又可以理解到這是在統計上才有意義, 對個案沒有意義.
lm(y~x) 就可以得到用 x 預測 y 的 linear model 的結果.
coef(lm(y~x)) 回報 coefficients beta0 和 beta1.
c(beta0, beta1) 用來產生向量.
舉例來說, x 和 y 用 c() 產生向量, 得出 linear model 後, model 再用 coef() 取出係數, 然後印出來.
x <- c(1, 2, 3, 4, 5)
y <- c(2, 3, 5, 7, 11)
# 建立線性回歸模型
model <- lm(y ~ x)
# 獲取模型係數
coefficients <- coef(model) # This gives c(beta0, beta1)
intercept <- coefficients[1] # beta0
slope <- coefficients[2] # beta1
# 印模型係數
print(intercept)
print(slope)
# OR 一行印模型係數
print(coefficients)
其中 <- 表示 assign, 正式名稱為賦值運算子 (assignment operator), 和 C 的 pointer 反方向.
用 Python 其實也不會變囉嗦. 以這個例子來說, Python 可以輕鬆應對. 雖然 R 確實更簡潔一點點.
import numpy as np
from sklearn.linear_model import LinearRegression
x = np.array([1, 2, 3, 4, 5])
y = np.array([2, 3, 5, 7, 11])
# 建立線性回歸模型
model = LinearRegression()
model.fit(x.reshape(-1, 1), y)
# 獲取模型係數
intercept = model.intercept_
slope = model.coef_[0]
# 印模型係數
print(f"Intercept (beta0): {intercept}")
print(f"Slope (beta1): {slope}")
# OR 一行印模型係數
print(model)