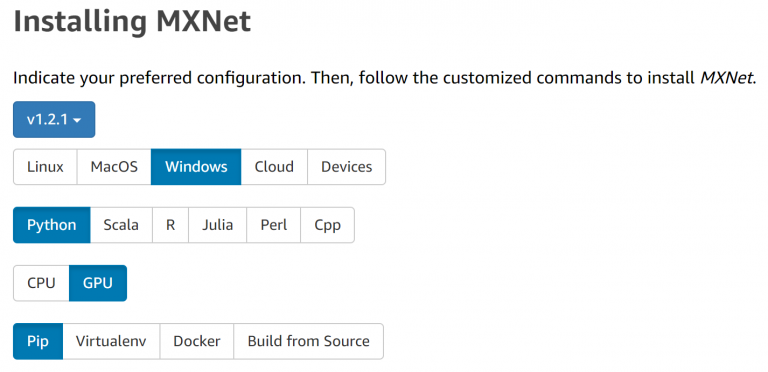
這個年假原本打算讀兩本書、 校稿兩篇專利 (?)、 準備一些美金看美股有沒有便宜可以撿、最後再看一下同事介紹的 DeepSeek 在幹啥?
不料就在年假的第一個周末, DeepSeek AI 突然直接攻佔各種新聞版面, 變得幾乎無人不知無人不曉. 週一晚上的美股 – 尤其是輝達價格大跳水! 這下我的好幾件事都連結在一起了. 因為我想讀的其中一本書就是 “輝達之道".
這本書原名 “The Nvidia Way", 作者是金泰 (Tae Kim), 譯者是洪世民和鍾玉玨. 本書非常值得推薦, 雖然翻譯有幾處比較不通順 – 不知道副詞子句是在講主詞還是受詞, 但整體可讀性沒問題. 每個人看這本書的觀點可能有些不同, 它可以是勵志的新創公司成功記、可以是黃仁勳發跡故事的側寫、或是一本 GPU 簡史. 對我來說, 它就是 Q&A. 解惑了我好幾個問題.
Q1. Nvidia 為何沒有變成一代拳王? MTK 蔡明介想過這個問題, 黃仁勳也想過. 兩個人遇到的狀況不同, 解法也不一樣. 黃仁勳認為會有一代拳王的是因為大家技術差不多, 但開發一顆 IC 要一年半的時間. 所以當你暫時領先, 對手的新產品就會比你厲害! 假設產品規格並沒有太大的改變, 只要規格疊得高, 那一代新人換舊人就是理所當然的.
黃仁勳解決這個問題的方法是成立不同 project, 開發週期彼此交錯, 共用資源和資訊, 隨時調整規格, 並且準時交貨. 從外界來看, Nvidia 推出產品的時間自然而然就縮短了, 對手很難在兩代產品交接的空檔中找到切入點! 當然這是在 graphic card 大混戰的時代才適用的策略. 如果大勢已定呢? MTK 理所當然去找下一個明星產品, 而老黃則是直接把現在的產品調整到直指未來.
他怎麼做到的呢? 當然就不是兩三句話那麼簡單. 總之我認為他好好地接受了不平凡的建議, 又壓榨出了驚人的成果. 像是光追, tensor, CUDA, NPU, GPU (替代 graphic card) 這些都是底下的人想出來, 再透過老黃鋼鐵的意志實現它. 底下會提到 Nvidia 發明了 GPU 這個名詞來和 graphic card 區隔.
Q2. 為何要叫做 GPU? Nvidia 的產品經理認為他們 graphic card 可以同時處理 4 個 pixel, 能做圖形的旋轉平移, 這些都取代了原本的 CPU 程式, 所以應該叫做 GPU. 於是老黃就在 1988 年 8 月宣稱他們的 GeForce 256 是全世界第一顆 GPU, 即使那顆 GPU 還是要下 register 才能叫它做事, 還不能真的寫高階程式語言.
Q3. 為何雲端運算需要 GPU? 這要先從高速運算說起. Nivia 的團隊在設計 Geforce 3 時, 為了解決 render 上較複雜的計算, 開發者藏了一些可編程的運算單元在圖形處理之中. 當然這代表 GPU 就有了一些浮點矩陣運算的能力. 即便只能用 OpenGL 或是 Nvidia 的 Cg (C for graphic) 來 coding, 至少硬體非常強大.
高速運算原本是 CPU 的市場, 強大的 CPU array 就是超級電腦. 當學者或研究單位擁有超級電腦, 就可以快速地完成複雜的計算. 但沒有被分配到這類珍貴資源的學者, 就算有很好的想法也無法領先發表論文, 輸家就永遠是輸家. 久而久之就形成了學術壟斷.
2002 年, 有位馬克哈里斯 (Mark Harris) 研究員發現許多科學家開始用 GPU 做 “非圖形" 的研究. 狀況就跟現在很多公司、大學都用 RTX4090 而不是 DGX B200 做 AI 實驗是一樣的道理 [1]. 所以他就架了一個 GPGPU.org (generla purpose GPU) 的網站, 幫助大家活用 GPU 來代替買不起的超級電腦. 接著 Nvidia 發現了這個網站, 招募哈里斯加入 NV50 (G80) 團隊.
G80 的 GPGPU 能力比過去更強大, 不再使用 Cg, 而是推出了 CUDA (Compute Unified Device Architecture). CUDA 呼叫 GPU 的 PTX 指令集, 讓大家不需要特別去學這個架構的組合語言, 而是有專屬的 compiler 可用. 黃仁勳說: “CUDA 讓我們的成本大為增加". 但是他們達到了目的: (1) 讓所有的人都可以用 CUDA, (2) 讓 CUDA 適用於所有領域. 於是有愈來愈多人發掘出 GPU 的用途, 從模擬新藥、挖礦 (虛擬貨幣) 到訓練 AI.
當然 Nvidia 的故事也不是都這麼正面. 他們發現科學家工程師只買電腦版 500 USD 的 GPU, 而不買他們更貴的伺服器版 2,000 USD 的 Tesla (p. 378). 於是 Nvidia 自己宣稱他們 PC 版的 floating 不太準, 伺服器版才準. 在被沃克教授證實並沒有不準後, Nvidia 改為在不影響圖形輸出的程度下把它改成不準. 沃克和它的團隊又再把它 patch 回來! 並且在他在藥廠的新工作中,買了成千上萬的電腦級 GPU 來建立 data center.
Q4. 為何大家都用 Nvidia 的 GPU 訓練 AI? 別家的卻不行? 這個問題一半的答案就是 CUDA, 它不是一張繪圖卡或是遊戲卡, 而是算力卡. 若只是要畫出滿屏的圖形, Intel 自己就可以做到了. Nvidia 預先看到這一點, 因此用 GPU 和圖形輸出做出區隔. 並且賣得超級貴. 別人的產品都是 ASP (平均銷售單價) 愈來愈低, Nvidia 主打愈賣愈高, “買愈多省愈多"!
回歸 AI 這個主題. 過去的 Machine Learning 都是先找特徵, 然後統計特徵值, 根據統計原理做分類. 直到 AlexNet 出現, 才有不找特徵, 讓系統根據 label 過的資料, 自己找出規則的 Deep Learning. 當然這就不得不歸功於當初 labeling 這些 database 的先驅李飛飛. 發明 AlexNet 的多倫多大學團隊 (當然包括其中一個學生叫做 Alex) 就是使用輝達的 GeForce 500 做訓練, 他們在第三屆 ImageNet 大賽, 成果遙遙領先其他舊演算法 10% 以上 (p.425).
從此以後, 大家都知道要用 GPU 做 Deep Learning (DL). Nvidia 也看到這個 AI 商機特別大. 因此再推出 CuDNN (CUDA Deep Neural Network) 強化對 AI 的支持度. 對於一般高速運算的市場, 硬體需要支援 FP32 或 FP64 (浮點 bit 數). 但是對於 Neural Network 的訓練來說, FP16 就夠用了. 因此 Nvidia 的 GPU 從 2016 年開始都支援 FP16. 而且還加入了 Tensor Core. 書上提到老黃臨時在 tape out 前幾個月說要加 Tensor, 大家怎麼趕工達標. 這個不是本文的重點就先略過.
Tensor Core 有什麼好處呢? 因為 DL model 裡面都是矩陣運算, 而 CUDA Core 只是浮點乘加器, 需要 CUDA compiler 來優化計算流程. 假如矩陣運算有特別的硬體, 那麼採用 CuDNN 來編 code 就可以更加地優化. P.433 說到,有 Tensor 快 3 倍. 這就解釋了為何大家都愛用 Nvidia 的 GPU 來開發 AI 軟體, 而不用市售的 NPU. 市售的 NPU 對於常用運算子的軟硬體優化差了 Nvidia 一大截. 所以做某些推論應用 (inference) 還可以, 整體而言是事倍倍功半半.
Q5. Nvidia 怎麼搭上 DPU? Mellanox 這家公司把 InfiniBand 這個標準做成高速網卡, 在數據中心可以 offload CPU 對網路封包處理的算力消耗. 雖然生意不錯, 但這家公司太小, 負擔不起高昂的研發費用, 最後只好賣公司. Nvidia, Intel, Xilinx 三家競標之下, Nvidia 看到它在數據中心的綜效, 因此花了每股 125 美元 (共 69 億美金) 標下股價 76.9 的 Mellanox.
接下來, 老黃又出來說我們發明了第一個 DPU. 當然, Nvidia 敢這樣講, 就是他們又投資了更多加速的軟硬體, 跟一般的 SmartNIC 做出區隔. 想要再重演一次“GPU 不等於繪圖卡”的劇本。
這本書的內容當然不只於此。或許可以用創業和經營事業的觀點再重新詮釋一次。像是保持扁平團隊,保証訊息一致,還有老黃偏執地好學等等。這部分就等我看完張忠謀自傳再來匯整好了。畢竟兩大管理者可以互相輝映。
[REF]