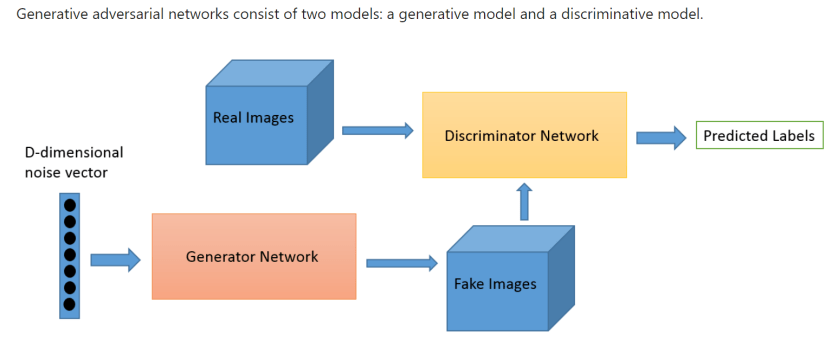
我想挑戰一面挖礦, 一面跑 AI training, 一面開艾爾登法環,… 不過看起來有點困難, 只好不跑老環了, 反正一直 “You Died". 好, 在此把 training 的步驟整理如下.
- 如先前所說, 用 Anaconda3 做出一個環境, 然後開 terminal.
- 到網路上下載訓練用的圖片. 根據原作者所述, 他用的 database 是 DF2K.DF2K is a merged training dataset consisting of 800 DIV2K training images and 2650 Flickr2K training images.
- 雖然不知道有什麼特殊之處, 總之這兩個 databse 的名稱長度不一樣, 我就直接把它們塞到同一個目錄.
新目錄的位置在主目錄下自己建一個 datasets. 再下面一層開個 DF2K 子目錄, 一層 DF2K_HR 子子目錄. 2K 照片全部放這裡. 然後在與 DF2K_HR 同層開個 DF2K_multiscale 目錄. 這樣下一階段就可以開始訓練了.
4. 訓練步驟參考 [1], 首先把每張圖做縮圖, 分成 0.75, 0.5, 0.33, 0.25 四種大小. 看起來有 rounding 到特定的數字, 而且有 floor = 400.
python scripts/generate_multiscale_DF2K.py --input datasets/DF2K/DF2K_HR --output datasets/DF2K/DF2K_multiscale
例如 000001.png 就生成 000001T0.png、000001T1.png、000001T2.png 、000001T2.png 四張不同尺寸的小圖.
| 2048×1356 |
1530×1017 |
1020×678 |
680×452 |
601×400 |
5. 然後把圖形全部切齊成同樣大小的方塊. 注意 DF2K_multiscale_sub 這個目錄要留給程式建, 自己先建好會報錯.
python scripts/extract_subimages.py --input datasets/DF2K/DF2K_multiscale --output datasets/DF2K/DF2K_multiscale_sub --crop_size 400 --step 200
這裡的第一個參數顯然就是要把圖形裁切成 400×400 的小圖. 第二個參數看程式註解: “step (int): Step for overlapped sliding window." 這個意思是每個小圖有 200 pixel 和另外一張裁切圖有重疊. However, 我必須說此處就丟掉一些重要的資訊, 我想想怎模申請專利好了~~~
[原始的小圖 xxxT2: 680×452]

T0 切成 35 個 400×400, T1 切成 15 個, T2 切成 6 個, T3 切成 2 個. T0 的前四張 400×400 長這樣. 也就是由左至右掃過原圖的上方.




6. 在前一個步驟, 很多 400×400 小塊的原稿在哪裡? 這個資訊 (metadata) 需要保留起來, 因此下面這個步驟的重點就是回溯紀錄 metadata.
python scripts/generate_meta_info.py --input datasets/DF2K/DF2K_HR, datasets/DF2K/DF2K_multiscale --root datasets/DF2K, datasets/DF2K --meta_info datasets/DF2K/meta_info/meta_info_DF2Kmultiscale.txt
7. 以上算是滿快就跑完了, 跟我打字的速度差不多. 接下來是重點, 作者的說明在不同版本有些許差異, 總之找到前面檔案總管節圖的那個目錄底下的 options, 裡面會有很多個 yml 檔. 以放大四倍來說, 需要改這兩個檔案, 確定目錄都對. 第一個訓練 generator, 第二個訓練 discrimator, 因此 pre-train 的檔案不同.
train_realesrnet_x4plus.yml
train_realesrgan_x4plus.yml
8. 接下來用 debug mode 跑一次,
python realesrgan/train.py -opt options/train_realesrnet_x4plus.yml --debug
馬上發現 Anaconda 的環境沒有安裝 cuda “Torch not compiled with CUDA enabled", 即使補安裝 cudatool, 也只是把 torch 版本由 1.10.2+CPU 變成 1.10.2, cuda 還是 unavailable.
(RealESRgan) C:\Users\ufoca\Real-ESRGAN>python
Python 3.8.12 (default, Oct 12 2021, 03:01:40) [MSC v.1916 64 bit (AMD64)] :: Anaconda, Inc. on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import torch
>>> print (torch.__version__)
1.10.2
>>> print (torch.cuda.is_available())
False
>>>
看起來要先下載正確版本. 參考 [2],[3],[4]. 網站 [4] 是 pytorch 官網, 似乎只要把自己環境設定對, 就可以用 UI 生成正確的安裝指令.
conda install pytorch==1.10.2 torchvision cudatoolkit=11.3 -c pytorch
不過這招其實沒用, [5] 說的才是對的. 要用 pip install, anaconda 本身的 server 只有 cpu 的 pytorch 可以選.
pip install torch==1.10.0+cu113 torchvision==0.11.1+cu113 torchaudio===0.10.0+cu113 -f https://download.pytorch.org/whl/cu113/torch_stable.html
另外, 我本來 pytorch 是 1.10.2, torchvision 是 0.11.3, 但上面那行貼了就會動. 安裝完跑出一些紅字說沒有檢查所有版本的相容性, 所以我又重新安裝成我的版號, 不過我不知道我的 torchaudio 應該要搭哪一版? 反而安裝不成功.
於是我還是用網路版本, 並且重跑一次
pip install -r requirements.txt
讓作者的檢查系統幫我微調一下版本. 總之, AI 的技術進步很快, 網路文章上的版號參考就好. 到時候要隨機應變.
9. 接者就不用跑 debug 版了. 改跑這條.
python realesrgan/train.py -opt options/train_realesrnet_x4plus.yml --auto_resume
我估計應該會做很久很久. 記錄一下起跑時間.
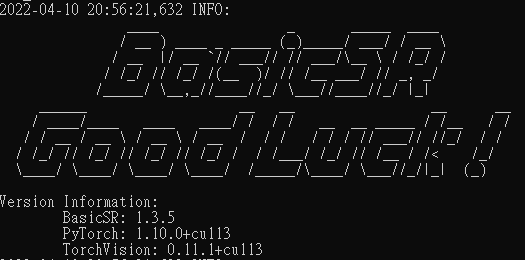
UI 顯示要跑 5 天半.
2022-04-10 21:48:02,327 INFO: [train..][epoch: 5, iter: 6,500, lr:(2.000e-04,)] [eta: 5 days, 10:47:47, time (data): 0.476 (0.002)] l_pix: 6.8241e-02
10. 然後是訓練 discriminator
python realesrgan/train.py -opt options/train_realesrgan_x4plus.yml --auto_resume
證明環境沒問題之後, 就可以自己動手腳去改 code 了.
[Note]
1. https://github.com/xinntao/Real-ESRGAN/blob/master/Training.md
2. https://towardsdatascience.com/setting-up-tensorflow-gpu-with-cuda-and-anaconda-onwindows-2ee9c39b5c44
3. https://varhowto.com/install-pytorch-cuda-10-0/
4. https://pytorch.org/
5. https://ithelp.ithome.com.tw/articles/10282119