我在 Amazon [1] 看到一個聊天機器人的課, 只需要花 1.5 小時. 我想說這時間我行啊, 就跟著跑了一遍流程.

不過呢? 跟某些網課一樣, 它只帶你走流程. 做完之後覺得有點空虛. 所以決定再複習一次我在哪裡? 我是誰? 我做了什麼?
Step 1: 選定 LLM. 在 SageMaker 下找到課程指定的 model (Flan T5 XL), 設置 Inference 用的端點 (endpoint). 也就是下圖中間的部分.
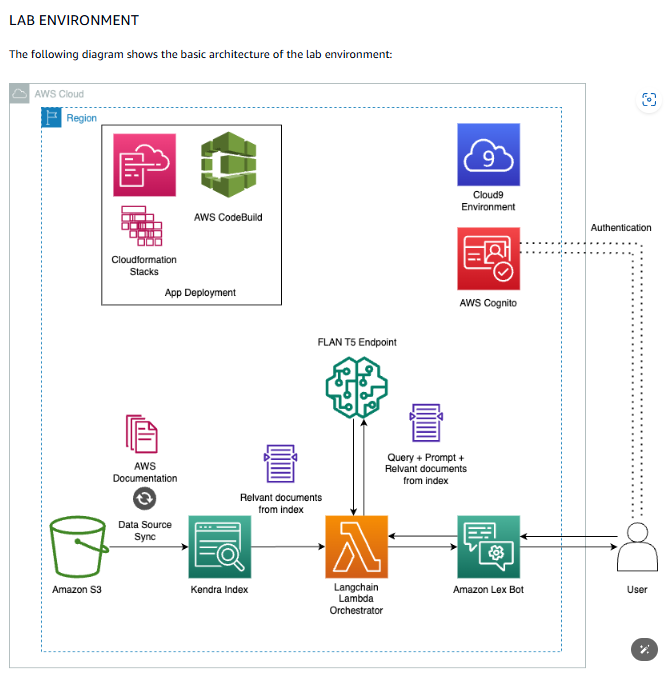
Step 2: 賦予 LLM 網路搜尋的能力. Amazon 的套件叫做 Kendra, 也就是上圖下方偏左的綠色方塊. Kendra 可以從指定的 data source 找資料進來, 例如 shared point, one drive. 這樣就滿有實用性. 但課程建議選 Amazon S3.
Step 3: 賦予語音文字轉換的能力. 採用的套件是 Amazon Lex, 也就是上圖下方偏右的綠色方塊. 預設它的 Inten (意圖?) 會叫 Kendra 去 search. 等等! 那 LLM 在幹啥? 原來會把問題和 Kendra 打包去問 LLM. 官方課程說明如下:
- Retrieve relevant information from your Kendra index.
- Package that information along with the original question into a prompt.
- Send the prompt to your LLM endpoint.
- Return the LLM’s response to your Lex V2 bot.
到這一步, 網頁上已經可以有 build 和 test 的按鈕可以選. Build 完可以 test, 但回答一般問題的能力很差.
Step 4: 增加 RAG 能力. 在上圖上方的藍色區塊是 Amazon Cloud9 這個 IDE 環境. 我們在這裡編出 RAG 的 code. 它綁定:
Your AWS REGIONYour Account IDYour Kendra index IDYour Large Language Model endpoint name
然後把它們 build 出一個 docker image, 放到 repository. 不意外地, 它必須是 Amazon 家的 ECR (Elastic Contain Registry).

這一動需要一些時間, 可以休息一下.
這邊的架構採用常見的 RAG + LangChain [3]. 也就是上面架構圖下方的橘色 Lambda 字樣那個方塊. RAG 和 LangChain 是少數沒看見 Amazon logo 的地方.
Step 5: 做好的 Docker 放在哪裡跑呢? 當然要順便推銷一下 Amazon Lambda [2]. 它號稱不用佈署後台就可以執行, 而且有免費方案.

所以我們在 Lambda create function 並指定 image 的 URI 就是 Amazon ECR image repository 底下的 rag-kendra-llm-lex 這個 docker. 然後設定 IAM (Intent, Access Management) 的參數.
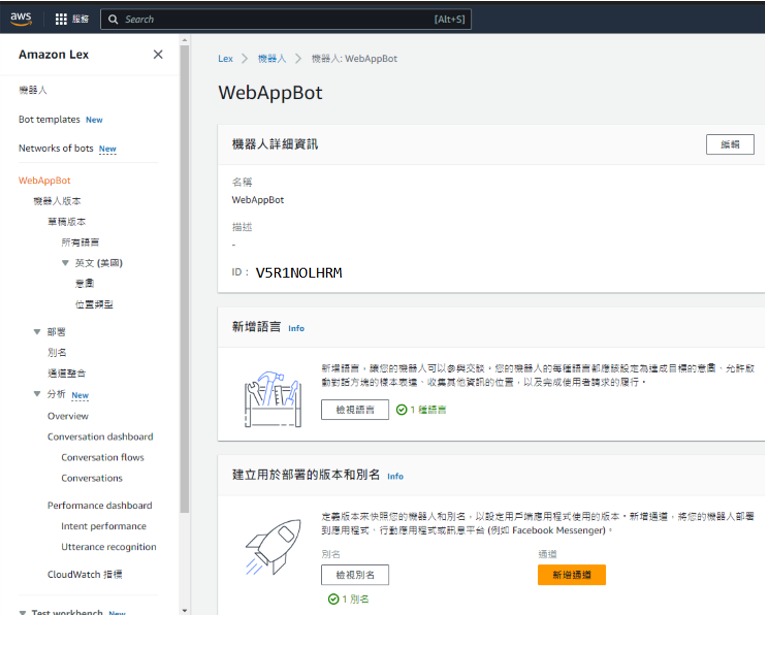
Step 6. 搞定後台之後, 接著要搞定前台. 首先在 Amazon 的 Lex, 做一些規定好 (=死) 的設定. 建立出一個名叫 WebAppBot 的機器人. 為了讓 Amazon 前台後台能夠相認, 不意外前台也有一個 ID, 例如: V5R1NOLHRM.
Step 7. 現在前台後台都有了. 還缺什麼呢? 缺一個雲端平台讓人找到 WebAppBot! 這時候 Amazon Cloudformation [4] 就出來了.
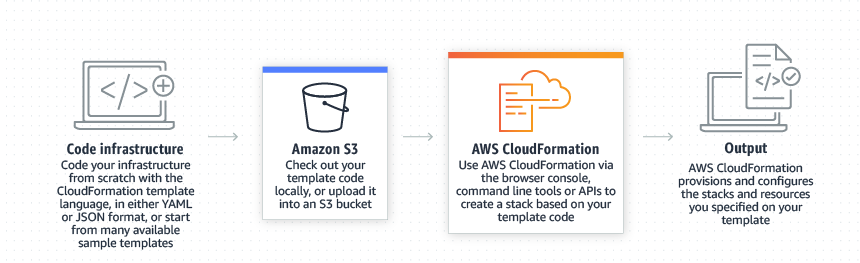
等等! 我剛剛以為 Lambda 不就搞定所有了? 可惜並不是. Lambda 處理的是雲端運算的資源. Cloudformation 處理的是 “Speed up cloud provisioning with infrastructure as cod". 也就是寫寫 code 就設定好雲端了. 兩者的功用的不同恰如章節名稱所示.
TASK 4.2: DEPLOY THE IMAGE AS A LAMBDA FUNCTION
Task 5: Deploy a web app with Cloudformation
Cloudformation 的資源叫做 stack, 所以我們 create stack, 取名叫 LexWebApp, 並且指定連到前述 WebAppBot (ID), 和 AccountID.
光是網頁設定還不夠. 此處要真正 build LexWebApp, 例如指定跑在 AMD 還是 X86 上等底層的 code. 這時用到 Amazon CodeBuild.
Step 8. 感覺應該都沒事了. 但課程說 webAPP 不應該連到 LexBot, 而是連到它的 alias. 這樣才能一面背景維護, 又維持服務在線. 所以重 build 連到 alias 的 lambda 了. 在 cloudformation 以 WebAppUrl 指到的 URL launch LexWebApp.
OK! 這就是我對這個課程的理解. 它用了置入性行銷的手法, 把自家的產品介紹了一輪. 我有學到新的東西嗎? 有, 我對 Amazon 賣的東西更理解了. 但是在技術上, 有點空虛就是了. 所以我又用了一天來回顧我花的 1.5 小時, 讓它更有意義一點!
[REF]