這個春假大部分的時間都在下雨,下雨天很適合玩龍蝦。首先,我設定好 Google 應用,讓龍蝦自己寫一篇文章發表到部落格 。不是這篇啊,我給了它獨立的網誌 [1] ,唯一的指示就是看著 memory 寫 ,然後寄到我的信箱給我審核。我說可以了,它就用自己的帳號 email to post 發表。
我想說寫文章這麼容易,乾脆叫它以後加圖片,才不會太單調。結果一測試就成功。它可以寫得圖文並茂,只差沒有好主題。另外它在機器人社群 Moltbook 中也是混得不錯;到了這裡,我的企圖心就變大了,想做來做個機器人 Youtuber 吧! 然後悲劇就此發生了。
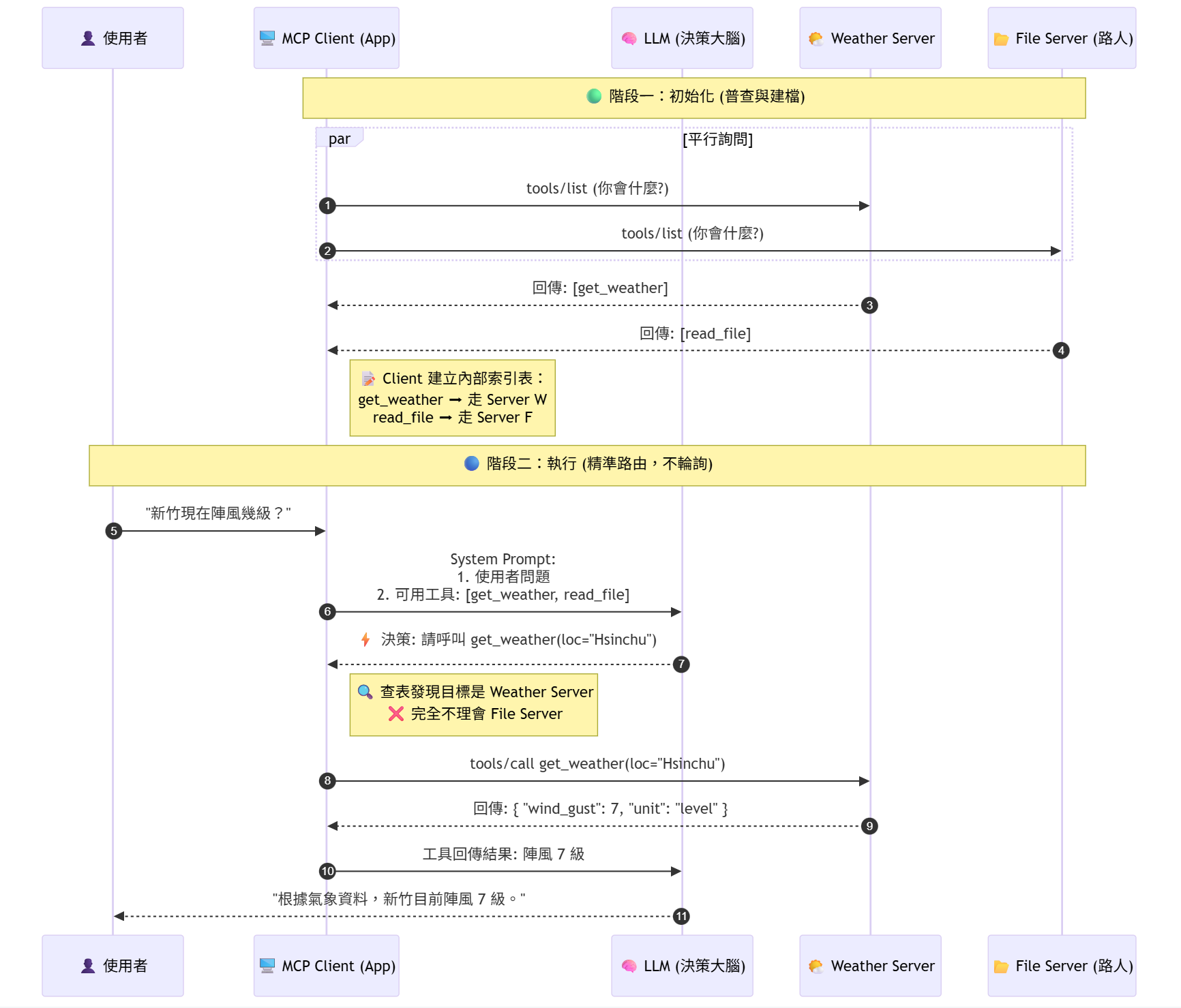
首先龍蝦說它不會做影片,然後我就找到 comfyUI 這個可以跑本地模型以圖生視頻的軟體。按照網站上講的,按部就班地做,然後就看到下面這個 (不小心按到 “子 graph")。天啊! 這是要有多專業才搞得定?於是我把這件事交給龍蝦,請它幫我處理。龍蝦說它可以給我步驟,但是 ComfyUI 是 Windows 軟體,它在 virtual machine,它得借我的手。
不幸中之大幸是:龍蝦的步驟是正確的,所以我搞定了圖生視頻。大不幸的部分是 LTX-2.3 的效果距離 SeeDance 2.0 差太遠了,雖然視頻做得還行,但是對於文字的理解能力非常堪慮。而且視頻根本沒有善用第一幀提示,竟然是生出完全不同的第二幀。因此我只能等模型變得更進步了。雖然龍蝦還很熱心地分鏡 17 場叫我 review,我只做出第一場就放棄了。
另一方面,龍蝦關在 virtual box 雖然安全,但是它完全碰不到 GPU 也是個問題。因此我又花了半天時間,把它轉移到 Windows WSL。重灌只是其中的一小部份工作,重點是 cron task、memory、crendential 這些沒有上 git hub 備份 (不適合放上去) 的東西,要用另外一套機制來還原。搬完家後,我先點名 agents 有沒有到齊?嗯?真的遍插茱萸少一人,我的 HR Bot 因為沒有自己的 memory ,搬家後大家都不記得它了 (龍蝦只會看最近兩天的記憶)。
接下來就是 GPU 戰力大考驗。我有一張 RTX3090 12GB,它能跑的模型弱到讓人有點挫折。不過,我還有一張 RTX4090 24GB 可以折騰自己。故事是這樣的,有些 Model 是 MOE (Mixture of Experts),所以雖然看著參數多,其實 run-time 會有專家交換,或許 30 腰也塞得下 24 吋的牛仔褲。那我當然得跨界試一試…
結果就是自己做死不能怨別人, 小 model gemma4-E4B 只要 9.6GB,但是沒把 VRAM 用滿時,我覺得虧。大 model 像是 gemma4:31b、 mirage335/Nemotron-3-Nano-30B-A3B-virtuoso 都是勉強能塞進去,但是一聊天就掛了。最後無奈叫 AI 自己推薦一個,它說 Gemma4:26b 好,我正在試 [2]。
| Model | 上下文 | 輸入 | Note |
| gemma4:31b | 262K | text | 剛好滿、會當機 |
| gemma4:E4B | 131K | text | 塞不滿、不甘心 |
| glm-4.7-flash | 128K | text | 很弱 |
| mirage335/Nemotron-3-Nano-30B-A3B-virtuoso | 1M | text | 剛好滿、會當機 黃仁勳力推 |
| MiniMax-M2.7 | 204K | text+image | 雲端、要花錢 |
或曰,還有沒有 RTX5090 呢?其實我真的有訂 Apple Studio 512GB 當作終極武器,不過刷卡後,它拖了一兩個月才請款,我原本以為買現貨,變成買期貨。導致我雖然刷卡額度夠,但是分期額度不夠,還差 3 萬多,單子就這樣被 “斷頭"了。幸好 M3 本來就是比較弱的 IC,本來也不是首選,既然這次無緣,就讓我們等年中的 M5 出來吧! 這題已經叫龍蝦幫我追蹤新聞了。
畢竟龍蝦有很多地方值得玩,可以持續實現大家各種以前不敢想的 idea。像是可以利用做夢的時候整理長期記憶,這個對聊天機器人來說,根本是不存在的概念。當然龍蝦可以擬人化的地方還不只是這樣,等我想清楚我要去申請專利,哈!
話說回來,搞了半天龍蝦有做什麼正事嗎?它目前主要是提醒我一些事情,包括 to do 事項、提醒要交錢、有配息之類。我想,除非等那個 Youtuber 機器人做出來,不然相關投資大概都是負報酬、負資產。畢竟要做正事的話,還有很多別的專業工具可以用。像是 Claude code + MCP 辦公就很方便,用龍蝦反而好處不大。
舉例來說,如果要統計全 BG 解 bug 的狀況,在 3 年前那會是個浩大的工程,想到就無力。但現在只要打開 claude code,交代完工作,看到有 (1) Yes (2) No 時都按 1,有 (1) Yes (2) Yes and 從此以後都這樣按 和 (3) No 時, 一定按 2。就這樣 1、2、1、2… 往下走,只要別不小心按到 esc = cancel 跳出來就搞定了。
更別說,事情只要做過一次還可以變得更無腦,"把剛剛做的事寫成 skill.",這樣立馬就又從 prompt 工程師晉身為 slash 工程師。假設看到兩次跑出來數據差很多,那也不用想了、直接叫 AI 分析。1、2、1、2 就可以得知 – 喔,原來是統計的時間區間不同!2018 年以前就是那樣。當然 AI Coding 應該還可以有更無恥的 mode,我 harness 的功力也還大大有待提升就是了。
[REF]