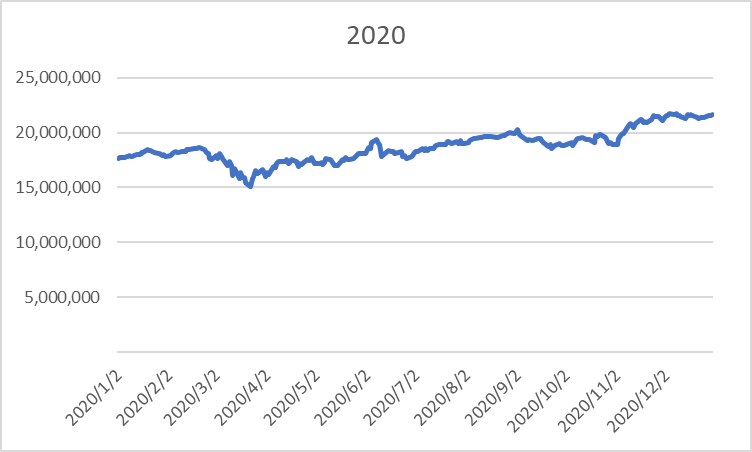
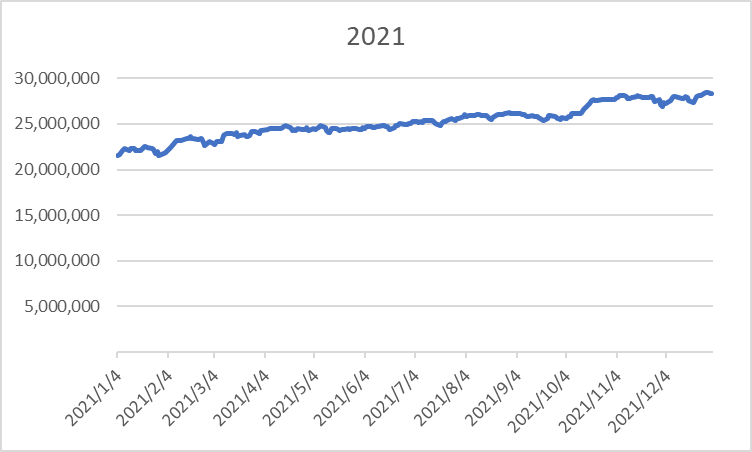
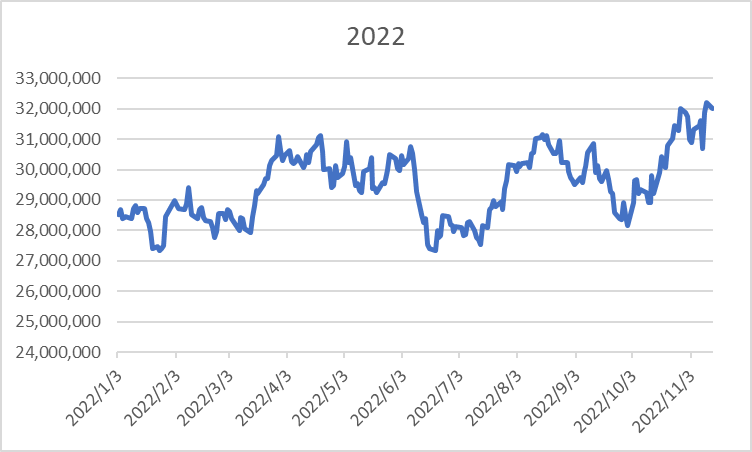
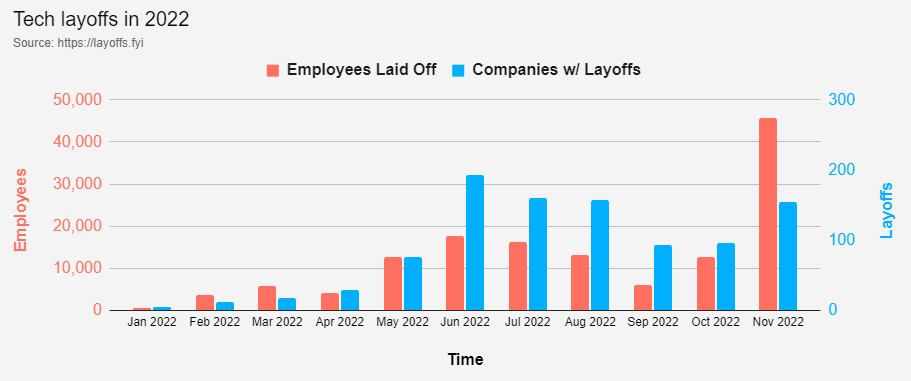
很多公司都裁員了, 但 Google 還沒裁. 所以網路上有一些討論. 我也趕快去 ping 一下親友有沒有事? 美國高科技業裁員的相關數據, 可以參考 https://layoffs.fyi/ 這個網站. XXX.fyi 這個網域有很多厲害的網站.
不管是退休或是被辭退, 都需要有現金流支撐. 網路上的討論中有人引用一畝三分地這個網站, 我點進去就看到一篇很有趣的文章. “[FI财务自由]净资产600万刀依然没有财务自由求解"[1]. 诶? 這麼有錢的人為何還不能沒工作? 太有趣了!
原 PO 身價近兩億台幣, 為何還不能財富自由呢? 原來他的 600 萬美元資產 (以下都是美元) 包括兩棟房子, 一棟自住, 一棟租人. 扣除 160 萬房貸, 淨值算 400 萬. 另外兩百萬是公司股票 (RSU=Restricted stock units) 100 萬 , 401K (退休金, 40萬), 股票與約當現金 (60 萬).
兩棟房子假設價值相等, 總值 400+160=560, 所以每棟 280 萬. 因為自住房不能當飯吃, 所以 600 萬當中, 有 280 萬是不能動的. 另外 280 萬有 160 萬房貸, 可以運用的部分約 280-160=120 萬 (賣掉房子就可以兌現). 另外 200 萬股票假設沒太大問題, 那麼原 PO 可運用資產是 120+200 = 320 萬.
原 PO 的房子能月租 4K, 相當於一年有 4K x 12 = 48K 的收益. 據說房租和物業稅 (proper tex = 房屋稅之類的 [2]) 支出相抵. 所以這 120 萬的部分等於沒有收入. 其他的投資有 200 萬, 假設這 200 萬元投資的獲利, 再扣掉支出還是正的 – 錢花不完, 那就符合我對財富自由的認知.
原 PO 說每年房貸要繳 80K (本利年繳 5% = 80K/160 萬). 日常開支和保險支出也是約 80K, 因此他的每年投資獲利要大於 16 萬, 就可以抵掉這兩個 8 萬. 故反推他要用 200 萬產生 16 萬股息的殖利率是:
16/200 = 8%
原 PO 的股票必須保證有 8% 的獲利才能夠不工作. 這個數字有機率達到, 但沒辦法保證年年都如此, 難怪他會覺得卡在那裡不上不下. 明明是個兩億萬富翁 (台幣), 卻得繼續工作到現金流轉正為止. 其實只要他房貸還完了, 他的股票只要年獲利 4% 就可以財務自由. 這差別滿大的.
有人建議他把出租的房子賣了, 改買南加. 這招我同學也在用. 他早年在南加買了很多間房 (house) 租給沒有身分的墨西哥人, 每戶每月能收幾 K 現金. 若原 PO 的幾百萬房產, 扣除自己住的那間不賣, 其他改買南加房 (一間 80 萬). 肯定能買個好幾間吧? 即使房貸, 房屋稅都不變, 現金流就大幅增加了.
看看在美國的大陸人, 想想跑不掉的台灣人. 我平常 “衝業績" 用的美股, 距離殖利率 4% 這個目標非常地遠. 手上最厲害的殼牌 (SHEL) 一年稅後配 3.4 % 就謝天謝地了. 至於 QQQ 則連 0.5% 都貢獻不了. 整個投資組合平均起來大概不到 2%, 也就是生不出多大的現金流.
若某人想要達到 Dcard 低標 – 當個有發言權的年收 300 萬大大, 又搭配上我的投資組合, 這樣反推本金就要來到 300 / 2% = 1,5000 萬 = 1.5億以上. 顯然, 這即使做到了也很蠢 – 只有資產負債表漂亮, 但現金流量表完全不及格. 然而, 只要現金殖利率調整到 3%, 整個投資的目標就拉近了 1/3, 效益很明顯啊!
當然, 也有人說可以每年賣一些股票變現, 或者以屋養老 (逆抵押) [3]. 但這也會遇到一個風險就是 – 萬一活得太久, 房子股票都賣光了人還沒死, 那可就真的要當下流老人了. 巴菲特每天吃漢堡喝可樂都活到 90 歲了. 變賣老本應該是老到不能動再考慮.
看完這篇 PO 文, 我想每個人在不同的時間, 都要考慮最適合自己的投資組合. 像是華倫存股的華倫大已經退休了, 他就是以高配息為主, 並不強調成長性. 像我還在工作, 打算就是維持 buy and hold, 但是多買些高殖利率資產, 花個幾年調出 3% 殖利率.
這陣子我也幫女兒買 S&P500 和 0050, 幫老婆買 VGLT (Vanguard Long-Term Treasury Index Fund ETF). 因為年輕人就是要投資大盤, 時間自然會帶來財富. 至於老婆跟我一樣老, 又非常保守, 所以我幫她選擇美國長期公債. 預期美國停止升息之後, 它能漲個 20%. 如果沒漲,…那就算了. 至少殖利率還有 3%. 這樣我就不會被罵~~
[REF]