假設我想知道整家公司的平均體重, 那麼只用一個部門來估計準不準呢? 答案是不準, 因為我們明明知道庶務二課或是秘書課的人都不胖, 所以據此估計出來 “滿帆商事" 的平均體重就會有點誤差. 這不需要數學好就可以知道.
反之, 如果根據一把抓起的豆子重量, 來估計一整桶豆子的重量範圍, 相對就比較準確了.
假設一把抓的豆子總共有 n = 100 顆, 平均數 m = 1g, 標準差 µ = 0.1g. 若整桶豆子約有 N = 10,000 顆, 可計算出樣本誤差 D = 1.96 x µ / sqrt(n) = 1.96 x 0.1 / 10 = 1.96 x 10-2.
為啥是 x 1.96 呢? 因為假設重量為 N(0,1) 的常態分佈, 在 95% 的範圍內, 標準差為 1.96. 當樣本數很大, 樣本誤差趨近於 0; 反之樣本數為 0 的時候, 樣本誤差趨近於無限大. 如果只有一個樣本, 樣本誤差大約是 2 倍 (1.96 倍) 標準差.
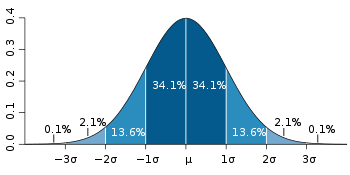
[本圖取自 WIKI 標準差]
換言之, 我們認為那桶豆子的平均重量為 m – D ~ m + D 之間, 也就是 1 – 1.96 x 10-2 ~1 + 1.96 x 10-2 或 0.9804~1.0196 g.
或曰, 怎麼和整桶豆子數量級 N 無關? 如果以井觀天, 以蠡測海, 也是用這個公式嗎? 非也, 這時候樣本誤差 D 還要乘上一個修正值 K = sqrt ((N – n) / (N – 1)).
把 Dnew 重寫一次得到Dnew = 1.96 x µ x K / sqrt (n).
直覺地說, 當 n 趨近於 N, 表示我一把已經把豆子抓光了, 那麼誤差應該修正為 K = 0 與 Dnew = 0. 因為 Dnew = 1.96 x µ x K / sqrt(n) .
如果真的由井底蛙來估計天空的大小, N >> n 將使得 K = 1. 因此我們知道 K 介於 0~1 之間,
為了抓一個手感, 我們假設 K = 0.49 的話, 則 N – n = 0.7 x (N -1), 0.3N = n – 0.7. 假設 N 和 n 都比較大, 那麼 n > 0.3N 是必須的. 也就是說, 想要讓修正值 K < 0.5, 那麼好歹得一把抓起 3 成的豆豆.
以上整理自 “真希望老師這樣教統計".


