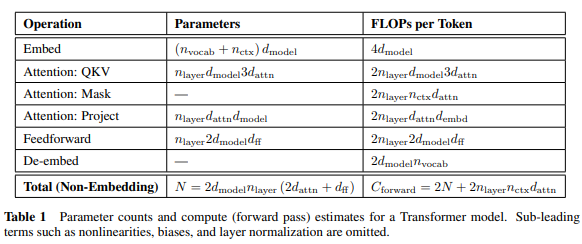
根據 [2], 跳過各種英文或數學, 3.3 或 5.1. 裡面都引用了 C = 6NBS. 其中 C = training computing, B = batch size, S = number of parameter updates (訓練總 token 數), and N = non-embedding parameter count (參數數量).
先前學過的 Tensorflow model training, 久而久之也還給老師了. 今天趁颱風假學習分散式的機器學習, 順便把基本功也補一些回來!
需要分散式學習的原因就是 AI (ML) model 太大了, 因此有各式各樣的方法把工作分散給不同的 CPU, GPU, TPU (後續用 NPU 涵蓋之). 分散的方法包括把 training data 分散給大量 NPU, 或是把 model 的不同層拆給不同的 NPU 做. 後者比較沒有參數及時互通的問題就略過不談.
Data 分散出去給不同的 NPU 學習, 最明顯的問題就是大家拿到的 data 不同, 算出來的 gradient 理論上也不同, 那要麼收斂到同一版呢? 解決這個問題的架構 (architecture) 有兩個大方向, 分別為 synchronous 和 Asynchronous 兩種.
Each worker independently fetches the latest parameters from the parameter servers and computes gradients based on a subset of training samples. It then sends the gradients back to the parameter server, which then updates its copy of the parameters with those gradients.