趁著尾牙等摃龜的空檔,把這篇的草稿丟給AI 重寫。雖然變得有點 WIKI化,不過稍微調整順序, 潤飾文字後,感覺還是滿易懂的。
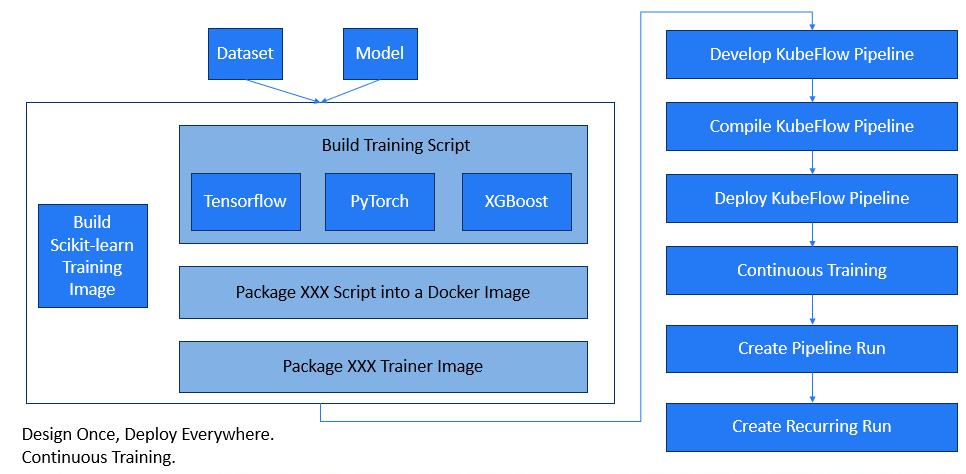
BentoML [1] 是一個開源的 ML 模型服務框架,名字源自日文「便當」,代表將所有組件打包在一起。相較於 Google Cloud 的 Kubeflow 解決方案 [2],BentoML 提供了不綁定特定雲服務的部署方式。
核心特點
- 模型管理
- 統一打包(模型 + 依賴)
- 版本控制
- 自動追蹤環境配置
- 框架支援
- 支援主流 ML 框架
- PyTorch
- TensorFlow
- scikit-learn
- XGBoost
- 多框架共存部署
- 服務效能
- 高性能 API 服務器
- 批量推理支援
- 自動負載均衡
- 部署便利性
- Docker 容器自動生成
- Kubernetes 整合支援
實作流程
1. 模型訓練與保存
# 訓練模型
from sklearn import svm, datasets
iris = datasets.load_iris()
clf = svm.SVC()
clf.fit(iris.data, iris.target)
# 保存模型
import bentoml
bentoml.sklearn.save_model("iris_clf", clf)
2. 模型管理
# 查看最新版本
bentoml models get iris_clf:latest
# 列出所有版本
bentoml models list
3. 預測方式
3.1 直接載入
loaded_model = bentoml.sklearn.load_model("iris_clf:latest")
result = loaded_model.predict([[5.9, 3.0, 5.1, 1.8]])
3.2 使用 Runner(推薦)
# 建立 Runner 實例
runner = bentoml.sklearn.get("iris_clf:latest").to_runner()
runner.init_local()
result = runner.predict.run([[5.9, 3.0, 5.1, 1.8]])
4. 服務部署
- 建立服務檔案 (
service.py):
import numpy as np
import bentoml
from bentoml.io import NumpyNdarray
iris_clf_runner = bentoml.sklearn.get("iris_clf:latest").to_runner()
svc = bentoml.Service("iris_classifier", runners=[iris_clf_runner])
@svc.api(input=NumpyNdarray(), output=NumpyNdarray())
def classify(input_series: np.ndarray) -> np.ndarray:
return iris_clf_runner.predict.run(input_series)
- 定義部署配置 (
bentofile.yaml):
service: "service.py:svc"
labels:
owner: bentoml-team
project: gallery
include:
- "*.py"
python:
packages:
- scikit-learn
- pandas
5. 本地測試服務
bentoml serve service.py:svc --reload
- Web UI: 訪問
http://127.0.0.1:3000或者 - API 調用:
$headers = @{"Content-Type" = "application/json"}
$data = "[[5.9, 3, 5.1, 1.8]]"
Invoke-WebRequest -Uri "http://127.0.0.1:3000/classify" -Method POST -Headers $headers -Body $data
6. 容器化部署
# 建立 Bento
bentoml build
# 容器化
bentoml containerize iris_classifier:latest
# 運行容器
docker run -p 3000:3000 iris_classifier:<tag>
7. 注意事項
- Docker 安裝需要提前準備,過程可能較長且需要重啟.
- 本地測試時需要注意防火牆設置.
- Runner 模式提供更好的資源管理和效能優化.
[REF]
- https://github.com/nogibjj/mlops-template
- Google 的 flow