先前做了一些 DeepSeek 算法上的研讀, 不過其實它的亮點還有很多. 這邊補充一小一大兩個東西. 第一個是 PTX, 第二個是蒸餾.
先前在 “輝達之道" 那篇稍微提到 PTX (Parallel Thread Execution). 在還沒有 CUDA 之前, 輝達就可以使用 Cg, OpenGL 或是 PTX 寫程式. 根據幾篇報導 [1-2] 指出, 這次 DeepSeek 不使用 CUDA, 直接使用 PTX 所以榨出更多的效能.
效能問題只是一個角度, 就好像說我的 code 都是用組合語言寫的, 所以效能更好. 人家可能說你神經病. 但跳過 CUDA 確實不一樣. 很多人認為, 就算大陸做出一個新模型, 效能更好, 還是逃不開輝達的 CUDA, 所以輝達的護城河仍在!像是我相當佩服得美投君 [3] 的新片也是這樣想.
[3] 影片 8’37″
不過我更願意相信, DeepSeek 有意擺脫 CUDA, 而不只是單純為了提升效能. 首先 PTX 類似 Java, 是 just in time 的編譯器 (virtual ISA), 針對不同的硬體可以做二次移植. 其次是 AMD GPU 和華為的 NPU 都支援 DeepSeek [4]. 華為的 Huawei Ascend NPU [5] 是什麼概念呢? 它可以中國產商不買輝達 GPU, 美國掐不住它的脖子 [6-7].
其次談一下蒸餾 (distillation). 我們知道這是一個老師教學生的演算法, 大模型教小模型, 小模型甚至能青出於藍, 但計算量就省下來了! DeepSeek 是一個大模型, 就算 MOE 等方法可以讓它只激活部分參數, 那還是很巨大啊!

但讓世人震撼的另外一面是 DeepSeek R1! 現在如果問 DeepSeek 關於它自己的技術, 它會有點故意誤導, 不知道是不是政治干擾? 根據 HuggingFace 上的說明: “DeepSeek-R1-Zero & DeepSeek-R1 are trained based on DeepSeek-V3-Base." [8] 但 DeepSeek 自己倒是說 “R1 可能是 DeepSeek 的早期版本或基础版本", 連自己的身世都胡扯, 哈!
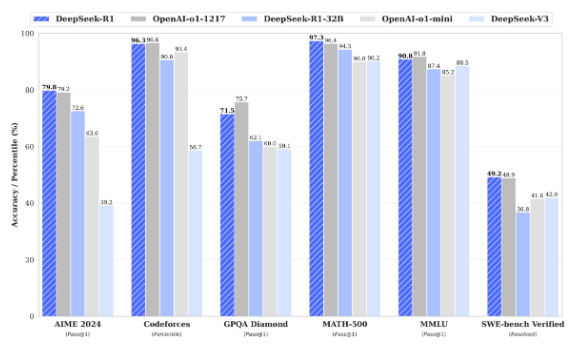
回到正題, R1 比 V3 更強大 [8], 它對標的是 OpenAI o1 – 1217. V3 是最右邊偏矮的那一個. AI 要做得好, 除了硬體和演算法, 就是要靠好的教材. V3 反映了演算法, R1 彰顯的就是好的教材.
R1 有兩個版本, DeepSeek R1 和 DeepSeek R1- Zero. 在官網講得有點不清楚, 我先引用曲博的影片 [9], 再補充名詞解釋.
R1-Zero = V3 + RL => 無盡的重複、可讀性差、語言混雜 => 有缺點.
R1 參考下圖.

[9] 17’19″
其中:
- RL = large-scale reinforcement learning, SFT = supervisor fine tuning,
- cold start = 通常是指參數是未訓練過、隨機的. 但 SFT 後再 cold start 有點怪怪的. 這部分還不理解.
- GRPO (group relative Policy Optimization) = 群內相對評比. 也就是標準答案不從外面給, 而是自己比較哪個答案好? 例如寫兩段 code, 誰的效率高自己知道.
接下來就是蒸餾的部分, DeepSeek 推出了它當老師教小模型的版本. 其中交 Qwen2.5-32B 就已經很厲害, 教 Llama 70B 的部分, 在下表 [8] 的比試幾乎全勝! 只有 CodeForces rating 這項還輸 o1-mini 而已.
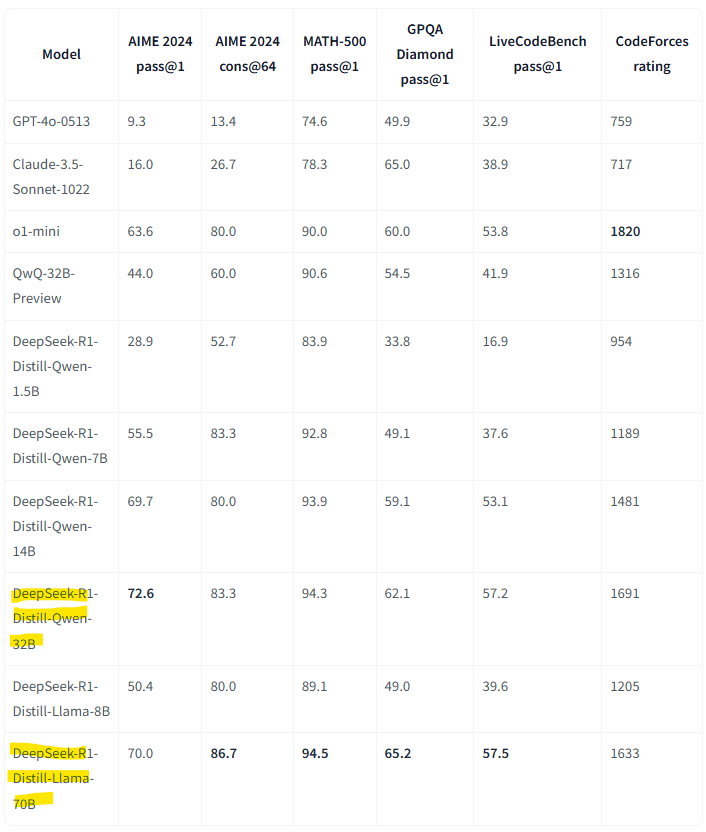
這表示什麼呢? 這說明就算你的系統還跑不了 V3 或是更優化的 R1, 只要用它去教小模型, 小模型也堪用. 像是它教出來的 Qwen 只有 1.5B, 好幾項測試都還贏 OpenAI 的 Claude 3.5 Sonnet, 這個還要花錢買耶 (我! QQ). Qwen 卻是 open source.
所以我感覺 DeepSeek 的發布不只是火力展示, 它的目的是要從算法、數據 (能教人是好老師) 兩方面展示不輸老美的優勢. 強強相爭, 以後 AI 會進步地更快吧! 只要不消滅人類都是好事!
[後記]
寫完之後, 發現老高也來評論了 [11]. 他講到一個值得補充的地方. ChatGPT 4o 對標 DeepSeek V3, 訴求全能. ChatGPT 01 對標 DeepSeek R1, 訴求推理過程 (chain of thought).
[REF]
- DeepSeek 绕开 CUDA 垄断,针对英伟达 PTX 进行优化实现最大性能,英伟达护城河还在吗
- https://technews.tw/2025/01/29/deepseek-bypass-cuda-and-using-ptx-for-better-optimization/
- https://www.youtube.com/watch?v=81cbmeXTQcg
- https://huggingface.co/deepseek-ai/DeepSeek-V3
- https://medium.com/huawei-developers/world-of-huawei-ascend-future-with-npus-5843c18993f3
- https://blog.csdn.net/qq_54958500/article/details/144064251
- https://udn.com/news/story/7333/8022387
- https://huggingface.co/deepseek-ai/DeepSeek-R1
- https://www.youtube.com/watch?v=spoPf8CjjBo
- https://www.bnext.com.tw/article/79507/claude-3.5-sonnet-best-ai?
- https://www.youtube.com/watch?v=uKBI1Ea8VO0