新 IC 非常順利, 好像不需要額外的關注. 於是來看一下 UCIE 說什麼? 上次研讀了 chiplet, 這次的 UCIE (universal Chiplet Interconnection Express) 就是用來規範 chiplet 如何連接. 特別有趣的是, 有別於上次舉的都是 AMD 的例子, UCIE 則是 Intel 所主導的. Contribution member [1] 包括咱們的同業: Broadcom, MTK, Marvell; IP 公司 Synopsys, Cadence 等等. 沒有 AMD!
按照 [2] 的說法, 大公司將比照 Apple, 跳過 IC 設計公司, 自己做產品. 在分工上, 依然維持 fabless, 例如 Apple, AMD 都是. 但是產品由自己定義, 甚至也不用讓 ODM 賺一手. 只要把 HW IP 兜起來, 然後找 TSMC 做 IC 和封測, 自己出 HWSD 設計系統, 發包給 OEM 生產即可. 這樣技術都在自己家裡.
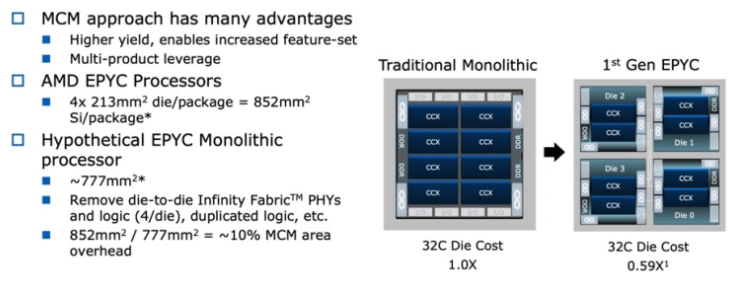
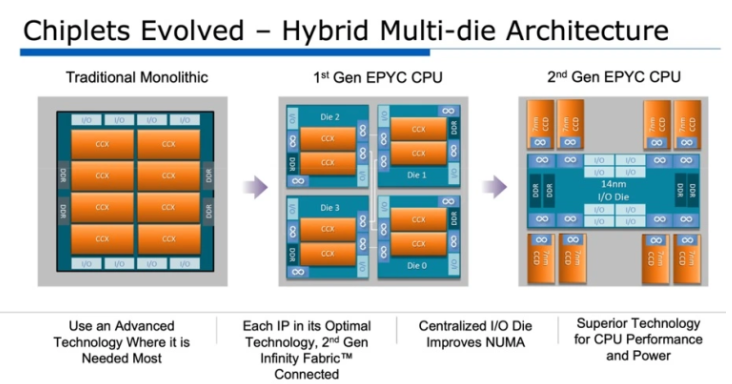
當然, 如果這個趨勢成真, 那 fabless IC design house 大概就沒飯吃了, 只能吃雜糧配菜. 舉例來說, Meta 要建立元宇宙用的資料中心, AMD 出 chiplet 來搶單, 第二代 EPYC 把 CPU/DDR 都用封好了, 外面有自家 interface 可以接網路 PHY, GPU, NPU 這些, layout 都固定了, 系統廠根本賺不到設計費. 更不干 design house 什麼事. 如果 IC design house 沒有符合 chiplet 互通標準的 die 可以賣給 AMD (舉此處資料中心的例子), AMD 絕不可能直接跟螃蟹公司買 Gigabit IC, 因為它不要封裝好的, 只要 known good die.
根據 UCIE 白皮書, 製程愈先進, 軟體愈貴 – 占用整個 design cost 的比重愈高, 驗證則居其次. 這個問題如何解決呢? 幫 SWSD 加薪嗎? 嗯, 但願如此. 白皮書的看法是簡化連接方式, 把它做到極簡, 就不容易出錯.

白皮書裡面有一張類似的圖, 但下圖這張 (取材自 [4]) 比較簡單. 在 UCIE 1.0 裡面, 最上層可以看到 PICE, CXL (Computer Express Link) 等知名 protocol. 其中 streaming protocol 是用來 mapping 到其他規格用的. 多種規格都以 256 byte Flow control Unit (FLIT) 為單位傳到 Die-to-Die Adapter. 其中 FDI 是 FlIT awared D2D interface. D2D adapter 負責處理繁瑣的資料處理, 然後透過 RDI (Raw D2D interface) 跟真正的 PHY 溝通.

資料傳到 PHY 這邊並不是終結, 而是 UCIE interconnect 到另外一個 die.把這些 die 都封裝起來, 是一個 2D/2.5D/3D 的 SOC. UCIE 在此提供 on package 的整合規範.
舉例來說, 下圖是一個伺服器的機架, 我們在電影裡也會看到. 主角想拔出一個抽屜 (drawer), 阻止 AI 電腦的運作. 在 UCIE 的架構下, 可能一個槽全是 (non-volatile) memory/storage, 另一槽全是 CPU/NPU 之類的. 彼此之間透過 UCIE off package 的方式溝通. 所以時間有限的話, 要拔對抽屜才能拯救世界!

最後, 這整件事對 fabless IC design house 有什麼意義呢? 那就是在大廠自己開 IC 的情況下, 設法做一些 chiplet 賣給他們, 多少能賺一點. 需要改變的是: 把手上的 IP 做成 chiplet die, 支援任何一種 chiplet interconnection protocol, e.g. UCIE, 並推銷出去. 我猜 CP 的驗證也要做得好, 但不用管 FT 了吧 (?).
[REF]