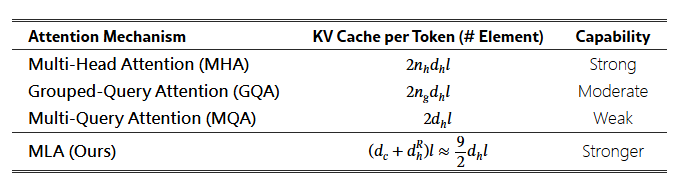
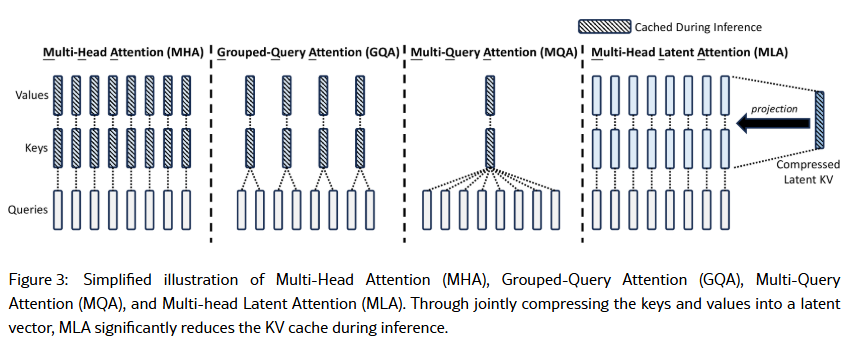
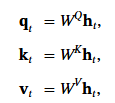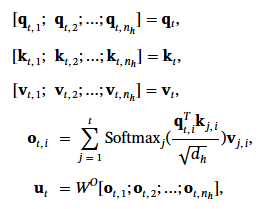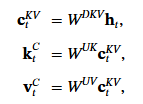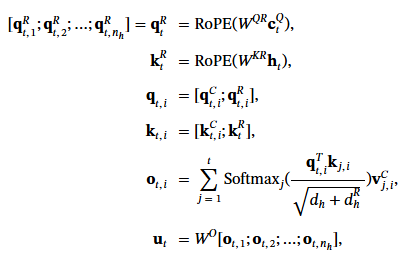DeepSeek 另外一個重點是 MOE (mixure of Expert). 從抽象觀念來理解, 就是說: 既然 Model 裡面有很多個 Expert, 問問題的時候, 只要把特定的專家叫起來回答就可以省能量, 加快反應速度.
LLM 的專家能力體現在 feed forward network (FFN) 這個部分. 以我的理解來說, 過去我們認為的類神經網路的確可以存儲知識, 只是差在沒有 transformer 來理解和表達語意. 人類的大腦也是分化為很多特定區域 [1], 因此動腦的時候的確不需要火力全開. 把 model 分為多個 expert 是很直覺的事.
好, 那麼誰決定選哪一些 expert 起來工作呢? 我們把它叫做 routed expert. 這個路由專家根據 input 把負責 sub-network 的串起來. 不過, 萬一串錯了, 雞同鴨講怎麼辦? 沒關係, 還有 shared expert, 它其實是個通才.
在下面的式子中, ut 代表第 t 個 token 對 FFN 的輸入. FFN(s) 代表 shared expert FFN, FFN(r) 代表 routed expet FFN, 看起來雖然有一點小複雜, 但其實 ht‘就是原始輸入 + routed FFN + shared FFN.
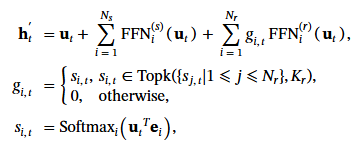
要加哪幾個 routed expert, 取決於 gi,t, 這個是什麼呢? 我們先解釋一下 e, 其他就很好理解了. e 表示 expert 的質心 (the centroid of the routed expert), 可以理解為 expert 的 “代表矩陣". 可能就像我們以前做 clustering, 每個 cluster 都要有一個中心 mean, 這樣才能分群.
當輸入 uT和 e 做矩陣相乘, 直覺可以知道它在判斷輸入 u 和 expert e 是否相似? si,t 就是這個輸出的 softmax 正規化. 既然有值就可以比大小, 最大的 k 個 (top k) si,t 個專家, gi,t不等於 0 就表示會被召喚.
到目前為止, 一切都很直覺. DeepSeek 最厲害在哪裡呢? 除了它把專家切得很細, 還要求挑選的專家要跨 device 做 load-balance. 當 device 數 >= 3, 效果會比較好. 為什麼要搞這個呢? 我認為就是美國不賣它厲害的 GPU 嘛! 每個 GPU 的 memory 都有限制, 所以當然產生了 3 個臭皮匠勝過一個諸葛亮的架構!
為了防止只有某幾個臭皮匠過勞, 或是臭皮匠集中在一起產生工作熱區, 或是遠距溝通但產生通訊熱區. DeepSeek 設計了一些 load balance 的機制. 因此我認為老美的管制是有效的. 如果有水冷的高級 GPU array 和 NPU, 基本上錢砸下去就有了. 因此相關的段落可以跳過. 但是 token dropping [2] 的部分值得一提.
即使上面已經盡力去做 load balance, 還是有可能某些 device 在 “訓練時" 超過運算 budget. 此時就把最沒有親和力 (affinity score, 與上下文相關性) 的 token 丟掉, 丟到平衡為止. 同時又保證至少 training sequence 中的 10% 絕對不能丟.
we drop tokens with the lowest affinity scores on each device until reaching the computational budget. In addition, we ensure that the tokens belonging to approximately 10% of the training sequences will never be dropped.
有了 MLA 和 MOE, DeepSeek 的兩大武器都稍微提到了. 隱藏在演算法後面的, 算是人海戰術清理訓練資料吧? Microsoft 的 PHI-2 系列就證明過: 只學有用的東西就好, 叫 AI 學一堆垃圾, 卻硬要訓練到收斂根本不環保. 下面稍微列出該論文 [3] 對 pre-trained 下的功夫, 我對於 DeepSeek 的追蹤就暫時告一段落.
While maintaining the same data processing stages as for DeepSeek 67B
(DeepSeek-AI, 2024), we extend the amount of data and elevate the data quality. In order to enlarge our pre-training corpus, we explore the potential of the internet data and optimize our cleaning processes, thus recovering a large amount of mistakenly deleted data. Moreover, we incorporate more Chinese data, aiming to better leverage the corpus available on the Chinese internet. In addition to the amount of data, we also focus on the data quality.
We enrich our pre-training corpus with high-quality data from various sources, and meanwhile improve the quality-based filtering algorithm. The improved algorithm ensures that a large amount of non-beneficial data will be removed, while the valuable data will be mostly retained. In addition, we filter out the contentious content from our pre-training corpus to mitigate the data bias introduced from specific regional cultures. A detailed discussion about the influence of this filtering strategy is presented in Appendix E.
[REF]
- 我讀 «大腦超載時代的思考學» – 2
- C. Riquelme, J. Puigcerver, B. Mustafa, M. Neumann, R. Jenatton, A. S. Pinto, D. Keysers, and N. Houlsby. Scaling vision with sparse mixture of experts.In Advances in Neural Information Processing Systems 34: Annual Conference on Neural Information Processing Systems 2021, NeurIPS 2021, pages 8583–8595
- https://arxiv.org/html/2405.04434v5