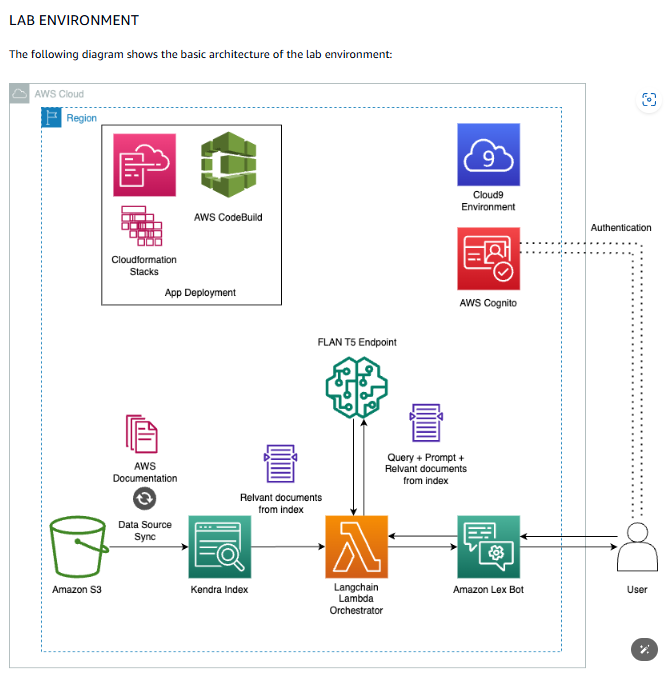
週日晚上做了一個夢。有位老先生用毛筆字寫了封信給我,署名林如松,要我照顧他的兒子。說這個兒子學習不好是因為某種心理疾病吧!總之懇請多多照顧等有上百來字。望文生義,那麼我在夢中的身份就是個導師了。
身為導師, 而不是醫師。我開始找醫學相關的線索。在一張可能是精神科醫師的桌子上,我發現了名片。上面寫了幾個小字說明醫師的專業。細節忘了,但其中 “止冰" 兩個字清楚地印入我的眼簾。這是什麼? 要阻止冰塊? 還是冰毒? 我納悶了一會兒,才恍然大悟是"治病" 的諧音.
病人因為精神疾病來求診,有點害羞會不想讓人知道,所以醫師就用某某人止冰來隱晦這件事! 想不到我只是做個夢,也會自編自導諧音梗啊! 在我破解了自己的梗之後,空中又傳來一個自問自答。"為什麼脖子太長不好? " 隔了一下,"因為好"頸" (景) 不長 (常)"。看來我的夢境是進入了諧音梗的 decorator [1].
等等! 一開始我有正經任務的啊! 怎麼跑題了? 想到這裡,世界又變得緊張嚴肅了。好像是初三23:59’57″ – 快初四 (出事)了! 我帶著兩三個人開始闖關,其中也不知道有沒有包括林小弟? 總之系統瞬間提示倒數 3 秒鐘,如果不在限時內讓機關套住一個掛勾,在我後面的人都會從平台上滑下去。正當我回頭叫其他人跟上來,倒數 3 秒已經 “加速" 結束了。我能跟大家說的話只有 一句 “來不及了"。
然而,即使倒數時間到了,我沒有完成任務,其他人也沒跟上,但好像並沒有發生什麼了不起的事? What not happened? 難道因為我們的 3 秒不是真的 3 秒,Dead line 也就不是 line 了嗎 ? 換言之,line 變成 non-linear,所以 dead 也就不 dead 了 !? 這麼一想好像也有道理。好比 nonlocal [2] 如字面所說,雖然不是 global,但肯定不是 local。事前有舖梗,後面就拗得過去。
看來這個夢中世界的 “人設" 很不靠譜啊!? 果然畫面再一轉,出現了那位忘記是自稱還是人稱喇賽之王的前同事 “肯", 帶著我們一行人小跑步穿越著商店街。沒有要 shopping,就是路過著日常騎樓下攤販。本來好像要堂堂展開的華麗冒險,就這樣被 apply(荒謬且搞笑) [3] 了.
Anyway,不管發生什麼事,我們都可以正向解讀。其實我們這位前同事去了谷歌。也許我祖先周公暗示著不管局勢多麼奇幻,還是要好好探索 (Google) 一下未知的領域。那些小攤位就不逛了,我們繼續前行,找出更重要的線索。既解決林小弟的困擾,幫助那位老林先生,同時也完成自己的任務。
[REF]
1. 在 Python 中,裝飾器(decorator) 的作用是用來修改或增強函數的行為。當你使用裝飾器時,原函數會被包裝到一個新的函數(通常是內部的 wrapper_func)中,因此裝飾器會影響函數的執行方式。例如:
from datetime import datetime
def 計時器(func):
def wrapper():
現在時間 = datetime.now()
小時 = 現在時間.hour
print (小時, "點了")
func()
return wrapper
@計時器
def 打招呼():
print("你好!")
打招呼()2. 在 Python 中,nonlocal 關鍵字用於在嵌套函數中聲明變數,讓內層函數可以修改外層(但非全局)作用域中的變數。
def 按讚():
次數 = 0
def comment_filter(好評):
nonlocal 次數
總類 = ["讚", "愛心", "加油"]
if 好評 in 總類:
次數 +=1
print(f"好評 {次數}")
return comment_filter
按 = 按讚()
按("哭")
按("愛心")3. .apply() 主要在 Pandas 中使用,是一個非常強大的函數,用於對 DataFrame 或 Series 進行數據處理。例如: df[‘成績’].apply(加分)
import pandas as pd
import math
data = {
'姓名': ['林明明', '李大同', '王小美'],
'成績': [85, 92, 5]
}
def 加分(row):
# 取得成績值
score = row['成績']
# 計算新成績
new_score = math.sqrt(score) * 10
return new_score
# 建立 DataFrame
df = pd.DataFrame(data)
# 使用 apply 並傳遞整個 DataFrame
df['新成績'] = df.apply(加分, axis=1)
print("DataFrame 內容:")
print(df)