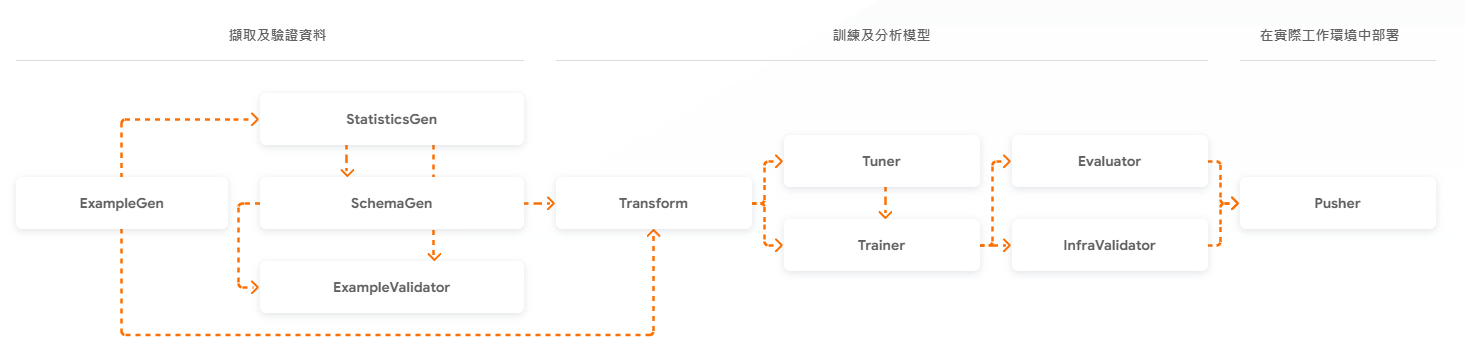
Coursera 有一門新的課 [1], 由該公司老闆 Andrew 介紹 CrewAI 來講課. 主要是講多個 LLM 怎麼應用. 課程不長, 有 Lab, 沒證書. 看在老闆推薦的份上, 我也來蹭一下.
用最簡單的話來講, 它的技術就是叫每個 Agent 執行一個 task. 雖然大家平平都是 LLM, 但是指定了不同的角色, 每個 agent 就會各自專注在它的 task 上, 達到互相幫忙的結果. 當然每個 agent 的排列方式 (hierachy) 會影響他們共事的結果.
可不可 search 網路? 需不需要 human input, 可不可以非同步? 這些在 CrewAI 這家公司的 library 中都可以設定. 每個 agent 透過 memory 互相溝通, 因此即使不指定誰 (agent) 要傳訊息給誰 (other agents), 資料也可以共用.
有個 Lab 很好玩, 就是建立一個 crew 去分析買股票的風險. 它的架構是 Crew 叫 agent 做 task. Task 就只是明訂工作內容 (description) 和預期成果 (expect output), 然後註明給哪個 agent. Agent 要指定 role, goal, backstroy (工作指導), 標記可以用那些 tools? 標記可不可以餵資料給別人 (delegation), log 要多詳細 (verbose).
from crewai import Crew, Process
from langchain_openai import ChatOpenAI
# Define the crew with agents and tasks
financial_trading_crew = Crew(
agents=[data_analyst_agent,
trading_strategy_agent,
execution_agent,
risk_management_agent],
tasks=[data_analysis_task,
strategy_development_task,
execution_planning_task,
risk_assessment_task],
manager_llm=ChatOpenAI(model="gpt-3.5-turbo",
temperature=0.7),
process=Process.hierarchical,
verbose=True
)
Crew kickoff 之後, agent 就會去做事. 至於要做什麼? 寫在 input string 裡, 相當於一個 prompt. 舉例指定用 1000 元去買 Nvidia, 風險承受度中等, 應該如何操作? 在課程的例子中, 因為指定 process 是 hierachy. 所以叫第一個 agent 去做 data analysis, 它有 search 網路的 tool, 因此就會各個網站 search Nvidia 的新聞. 總結出 10 條. 交給下一棒 Trade agent.
Trade agent 的工作是要分析標的物的統計值, 它也有網路工具. 所以它也去找了一堆網站. 總結出 Nvidia 的評價.
Based on the information gathered from various analyst forecasts and recommendations, the average 12-month price target for NVDA is $130.68, with the highest target being $200.00 and the lowest at $90.00. The consensus rating for NVDA is “Strong Buy," supported by 38 buy ratings and 3 hold ratings. The stock has a current price of $135.58. The analysis suggests that there is a potential -3.61% downside from the current price based on the average price target. The historical performance of NVDA shows consistent outperformance relative to the industry.
接一下到了 execution agent. 它有甚麼大膽的創見嗎? 沒有. 即使它收到這麼明顯地看多訊息: Considering the historical performance and analyst forecasts, developing a trading strategy that aligns with the bullish sentiment towards NVDA could be a profitable approach, especially for day trading preferences.
它還是說我要上網查看看, 然後歸納出 5 點結論:
Execution Plan for NVDA:
1. Utilize historical performance data to identify key trends and patterns in NVDA’s stock price movements.
2. Implement a strategy that leverages the ‘Strong Buy’ recommendation and average 12-month price target of $130.68.
3. Monitor market trends and movements closely to capitalize on potential trading opportunities presented by NVDA’s growth potential.
4. Develop a risk management strategy that aligns with the user-defined risk tolerance (Medium) and trading preferences (Day Trading).
5. Regularly review and adjust the execution plan based on new market data and insights to optimize trading outcomes for NVDA.
接著回到 Crew. 它根據風險承受度為 Medium 這個條件, 再上網去跑一輪. 對每個網站的內容做一個小結論. 最後叫 risk management agent 彙總, 結果就是給安全牌 (因為風險承受度不高).
Overall, the risk analysis for NVDA’s trading strategies should focus on understanding the potential risks associated with each strategy, assessing the firm’s risk tolerance, and implementing appropriate safeguards to manage and mitigate risks effectively.
我認為畢竟 Crew 收到的指令就是風險承受度中等而已. 已經預設立場, 不用問 AI 也知道結果. 當我把風險承受度改為 Ultra High 重跑一次. 這次它的結論就變狠了! 建議了一些選擇權策略: Straddle Strategy、Iron Condor Strategy 、Long Call Butterfly Spread Strategy、LEAPS Contracts Strategy 等等.
這告訴我們兩件事.:
- CrewAI 使用 multi LLM 的功效很強大. 大家做完自己的事就交給同事 (co-worker), 各司其職. 可以用同一個 LLM 做出一群同事開會的效果!
- 你跟 AI 講我風險承受度低, AI 就叫你保守. 你說你不怕死, AI 就叫你玩選擇權. 這些不用問 AI, 應該是問施主你自己就好了.
[REF]
- https://www.coursera.org/learn/multi-ai-agent-systems-with-crewai/home/welcome