RAG (Retrieval-Augmented Generation) 大家應該都知道了。至於 FAISS 是 Facebook AI Research(FAIR)開發的技術,主要用途是對海量高維度的資料作出相似度的比較。由於我是第一次看到 RAG 和 FAISS (Facebook AI Similarity Search) 一起用,所以做個筆記。
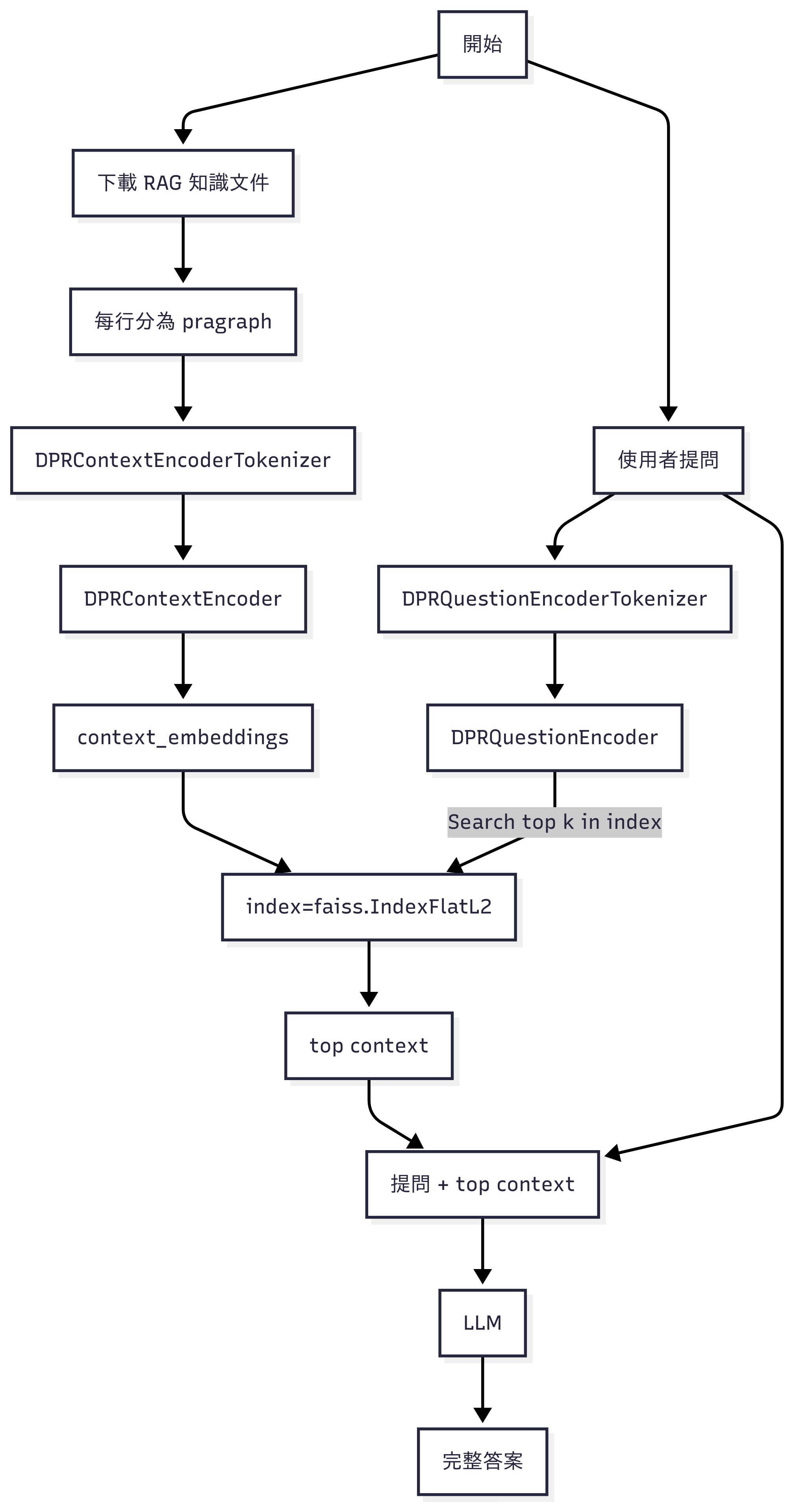
基本上 RAG 的知識庫可能是一本書、一本使用手冊、一堆 Facebook 的用戶資料等等。它們先分為不同的小段落,然後 tokenize,每個段落再 encode 為一個向量。同理,對使用者提問也做同樣的事,但此處理解為只產生一個向量。
由於知識庫的向量筆數很多, FAISS 為他們製作 Index。提問的向量用 FAISS 的函數中找出最接近的幾筆最相關的向量,再根據 index 反查出 text 原文。然後把 text 和使用者提問合在一起去問 LLM。
對 LLM 來說,它可以有自己的 tokenizer。總之,RAG 已經功成身退了。
假如不用 FAISS,純靠 Pytorch 的話,那麼要自己用 dot product 去比較相似性。因為每個 word 就可能對應到一個高維的 token,所以每個 pragraph 的向量就是所有組成 pragraph 的 word 的向量的平均值。
最後補充 DPR (Dense Passage Retriever)。顯然,它對於 question 和 context (passage) 用了兩套函數 – 所謂 dual encoder [1]。我們可以想像,對於 question 的編碼應該要力求精準,但是對於參考文件這部分,如果是一本百科全書、或是整個資料庫,那編碼時主要是求快!所以兩邊的編碼方式不太一樣、甚至 tokenizer 不太一樣 (但是相容) 應該也是合理的。
[REF]
