DeepSeek 問世後, 很多人討論它需要多少計算量? 我在此做個小整理.
基本上, 而一個 neural node 至少有 weighting 和 bias 要訓練. 而每層輸出共用一個 bias. 請 DeepSeek R1 想了 17 秒, 整理如下:
- 對於 Dense layer, 參數 = Node 數 + 1.
- 對於 convolution layer, 參數 = channel 數 * width * height + 1.
- 對於 RNN layer, 參數 = (輸入維度 + hidden state 維度 h) * h + h.
- 對於 LSTM, 參數=RNN * 4.
- 對於 L 層 transformer, 參數 = L * (12h2 + 13h) * Vh ~= 12Lh2 , 其中 V 是 vocabulary size (詞表). [3]
如果是做研究, 可能要參考 [2] 的表 1.
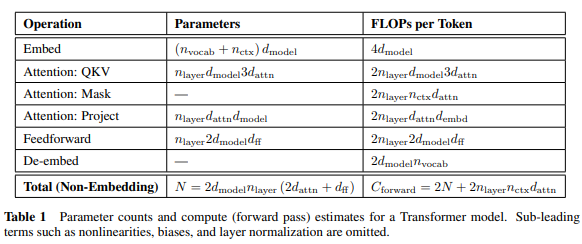
不管是哪一種 weighting parameter, 只要可以被訓練, 我們就算它一個參數. 至於不能訓練的, 像是 ReLU, 這些都不會列入參數, 只會佔據 memory 和 CPU time.
接下來的問題是每個參數要被算幾次才完成 training. 如果去問 AI 的話, 有些回答真的很離譜, 像是 Gemini 算出來比別人大好幾個數量級; 有些 model 會說要除以 batch size. 實際上 batch size 只影響 gradient 的更新頻率. batch 愈多次應該要乘愈多次而不是除. 所以還是問人類比較可靠 [3], DeepSeek R1 也還行, 只是它想了 128 秒.
FLOP s≈ 6 × 參數數量 × 訓練總 token 總數.
例如 GPT-3 175B 參數, 訓練 300B token, 需要 3.15 * 1023 FLOPS. 和官方公布的 3.14* 1023 FLOPS 接近.
其中 6 來自 forward (矩陣, activation) 2 次計算和 backward (梯度, 參數更新) 的 4 次相加. 至於訓練總 token 數, 其實已經吸收了 batch size 參數. 這邊再找個證據.
根據 [2], 跳過各種英文或數學, 3.3 或 5.1. 裡面都引用了 C = 6NBS. 其中 C = training computing, B = batch size, S = number of parameter updates (訓練總 token 數), and N = non-embedding parameter count (參數數量).
什麼是 non-embedding parameter? 就是所有的 parameter 扣掉 token 和 position embedding . 包括:
- Dense/Linear layers
- Attention layers
- Convolutional layers
- Batch normalization layers
- Any other trainable layers except embeddings
另外根據 Chinchilla 法則 [5], 訓練量應為參數的 20 倍. 所以 BS = 20N. 前面提到的 GPT-3 175B, 大約需要 3500 B token 的訓練才達到最佳效果. 它只訓練了 300B token, 理論上還有進步空間. 據說這是因為 GPT-3 發表於 2020 年, 而 Chinchilla 法則發表於 2022 年.
再回到風暴的起點, Deepseek 自稱是用 2.788K (pre-train 2664K) H800 GPU hours train 14.8 T tokens. 然而, 如果用上面的 6ND, 搭配 H800 Spec. 和論文中的數據 [7], MFU (Model FLOPS Utilization) 會超過 100%, 完全不合理.
MFU = 訓練需要的算力 / GPU 提供的算力 = (6 * 14.8T * 671B) / (2664 K Hours * 3600 second/Hours * 3026 TFLOPS) = 205%.
其中 MOE, MLA, MTP 可能有省到算力, 但就算把 MFU 壓到 100% 都解釋不通. 當然也可以說 DeepSeek 說謊 – 短報時數. 解決不了問題就解決人. 哈!
歸納起來, 此時不能用 6ND, 要參考 [8]. 用 “3 * 計算 Deepseek v3 的所有 forward 操作" 來代替 6ND. 如此就可以算出 MFU = 35~45% [6], 這樣起碼是落在合理範圍 (< 60%).
其實 [3] 和 [6] 都寫得很好, [6] 尤其完整. 不過我悶著頭寫了一大段才 reference 到他們, 只好改一改重點, 讓它們當配角了.
附帶一提. GPU 卡上的 RAM size, 決定了要用幾張卡才塞得下整個 model 的參數. Training 時要存 weighting, activation function, optimizer, gradient, 抓個 4 倍. Inference 時需要weighting, activation 和 bias. 抓 2.5 倍. 這是一般狀況, 非特別指DeepSeek.
[REF]
- GPT-3, The Model Simply Knows! – Analixa
- Scaling Laws for Neural Language Models
- AI大模型训练相关参数如何估算?有这一篇就够了
- https://zhuanlan.zhihu.com/p/606038646
- https://arxiv.org/pdf/2203.15556
- 【LLM 專欄】Deepseek v3 的訓練時間到底合不合理?淺談 LLM Training efficiency
- https://en.wikipedia.org/wiki/DeepSeek
- https://zhuanlan.zhihu.com/p/16445683081
