聽說 Google 喜歡用自己的 tool, 跟外面的世界都不一樣, 不過這方面我們就不深究了. 本篇專門看 Tensorflow Extended (TFX) 這個 platform 包含那些東西. 就算是我們用不到這套 tool, 也能夠從它的架構複雜度, 理解到為何 Machine Learning 的 code size 只佔整套 AI 系統 5% 的原因.
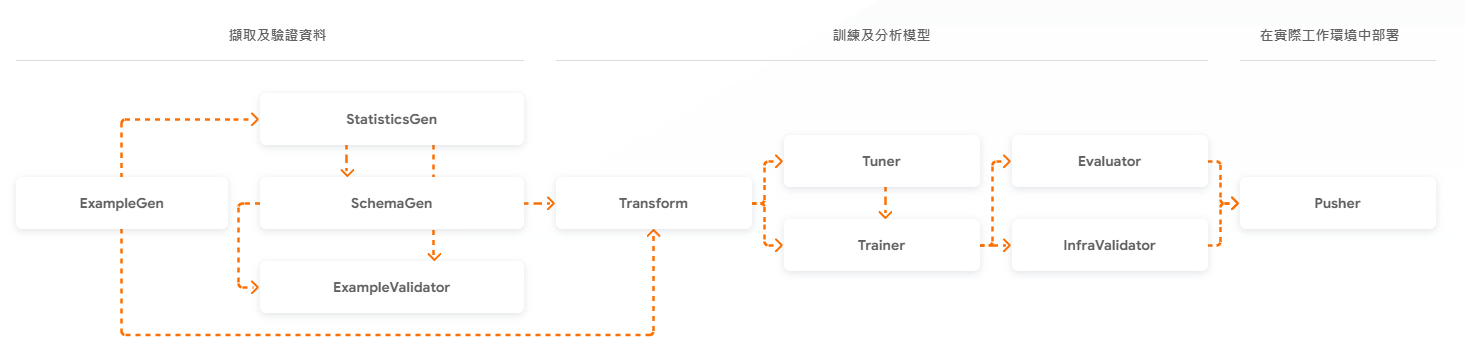
本圖取材自 https://www.tensorflow.org/tfx?hl=zh-tw
其中幾個重點用我的話翻譯如下:
ExampleGenerator – 攝取 (ingest) 資料, 區分成 training set 和 evaluation sets.
StatisticsGen – 產生數據集的統計資料. (最大值, 均值, 缺值….etc.)
SchemaGen – 對於數據集 (dataset) 產生 schema , 各種數據的 type (e.g. floating).
ExampleValidator – 在數據集抓出異常資料.
Transform – feature engineering. 抓出 feature, 進行轉換.
Tuner – 找出最佳 hyper parameter 參數給 Trainer 用
Trainer – 實際訓練 model.
Evaluator – 評估 model 是否比 baseline 好
InfraValidator – 將 ExampleGen 輸出的合格 data 餵給 Trainer, 測試 model 是否能正確運行?
Pusher – 將 InfraValidator 驗證過的 model push 到 deployment 環境.
BulkInferrer – 終於可以做大量的 inference 了.
除了測試數據有沒有問題? model 有沒有問題? 後續還要有追蹤機制, 看看 model 是否不準了? 不準的原因看是 data drift 還是 data skew. 然後線上做更正處理. 總不能老是暫停服務吧! CI/CD 這部分就屬於 MLOP (Machine Learning Operation) Level 2 的範圍. 夭壽的是還有 level 3.
Data drift 包括 feature drift 和 concept drift. 前者像是叫外送的變多了, 所以交通流量和 training model 時已經不同. 後者像是病毒特徵被抓到後, 新的病毒把特徵改了, 所以舊 model 偵測不到. 輸出造成輸入的改變, 所以叫做 concept drift.
Data Skew 是說每個地區的使用習慣不同, 所以某特定區域就特別不適合先前訓練出來的 model. 像是台灣學生有午睡時間, 此時大家都沒有活動, 對世界其他地方就是一種異常. 這種狀況也需要線上監控把問題抓出來, 最後可能是加個 feature (location) 重 train.
一般人都不會想到還需要動態檢測 model 合不合用? 想想這還真是一個巨大的成本.
