原本寫完兩篇 R, 就要來寫 R2, 我覺得這個哏不錯! 不過呢, 因為寫著寫著歪樓了, 所以把那邊的主題讓給 P-value, R2 放到後面來.
前面說到 P-value 用來衡量變數的顯著性. 由於我舉的是單一變數的 t-test, 好像 p-value 就足以解釋整個 model. 但真正能解釋整個 model 的是 R2 , 說明如下. 假設:

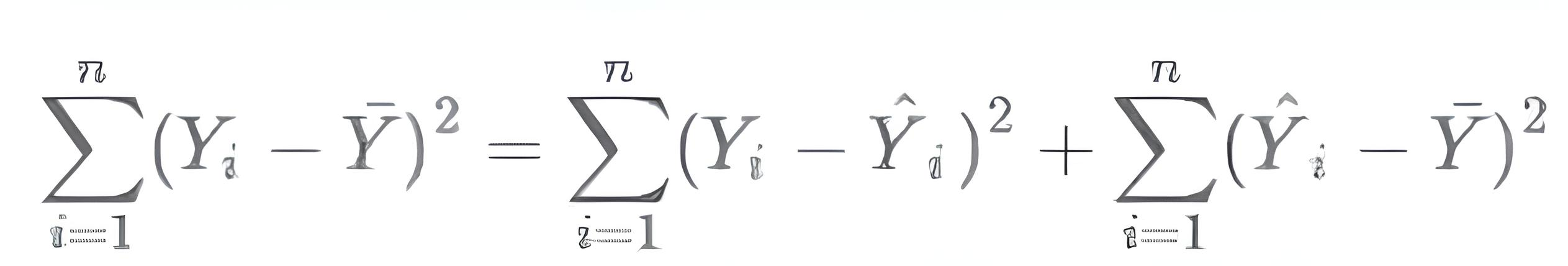
全部的誤差 SST = SSR + SSE .
SSR = residual variation = model 無法解釋的 (實際觀測值 – 模型預測值)
SSE = regression model variation = model 解釋掉的部分 (模型預測值 – y 的平均值)
R2 代表模型解釋變異的能力, 所以是 model 可以解釋的變異的比重 = SSE / SST = 1 – SSR / SST. 所以怎麼看 R 都是介於 0~1 之間. R 越接近 1, 表示 model 解釋得更好.
換個生活化的例子來說明.
- 假設抽樣調查了三對父子, 記下父親與兒子的身高 (單位:公分):
| 父親身高 (x) | 兒子身高 (y) |
|---|---|
| 170 | 172 |
| 175 | 177 |
| 180 | 179 |
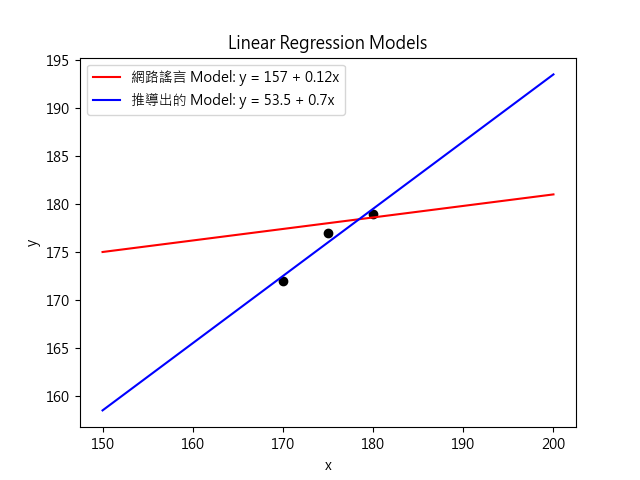
- 新手根據網路謠言, 建構了下面這個回歸模型:
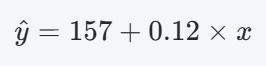
- 我們來檢驗看看. 首先將每個父親的身高 x 帶入計算, 預測兒子身高 y^.
| 父親身高 (x) | 兒子實際身高 (y) | 預測兒子身高 y^ |
| 170 | 172 | 177.4 |
| 175 | 177 | 178 |
| 180 | 179 | 178.6 |
- 計算 R2
- 計算 yˉ= (172+177+179) /3 =528/3 ≈ 176 — 兒子的平均身高
- 計算 SST (Sum of squared Total) = (172−176)2 + (177−176)2 + (179−176)2 = (−4)2+(1)2+(3)2=16+1+9=26 — 兒子的身高和平均身高的差的平方和
- 計算 SSR (Sum of Squared Residual) = (172-177.4)2 + (177-178)2 + (179-178.6)2 = 29.16+1+0.16=30.32 — 兒子的身高和預測身高的差的平方和
R2 = 1 – SST / SSR = 1 – 30.32 /26 = 1 – 1.166 ≈ -0.166
因為 R2 < 0, 或 SST > SSR, 等於是說: 全部猜平均身高的話, 還比用 model 估來得準. 所以此 model 很不好!
如果我們一項一項分開算. SSE = (177.4−176)2 + (178−176)2 + (178.6−176)2 = 1+4+6.76 = 12.72
SST ≠ SSR + SSE 或 26 ≠30.32 + 12.72
為何會有這樣的結果呢? 主要是這個 model 不正確, 所以什麼都解釋不了. 發生這種問題可能的原因包括:
- 模型套錯:使用的模型和資料的型態根本不吻合(例如線性模型去解釋非線性資料)
- 資料點太少:樣本數極少,容易受到極端值影響
- 預測變數選錯:所用的 x、公式、或回歸參數明顯偏離資料特性
- 資料雜訊過高:資料本身的變異無法用簡單模型捕捉
讓我們只用這三筆資料來生成合理的 linear regression model, 並重新計算 R2. 這個部分就請 AI 來執行了.
1. 原始資料
| 父親身高 (xx) | 兒子身高 (yy) |
|---|---|
| 170 | 172 |
| 175 | 177 |
| 180 | 179 |
2. 計算步驟
步驟一:計算平均值

步驟二:計算斜率 (b)
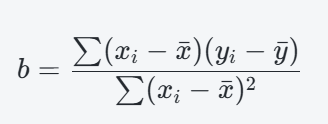
b=0.7
步驟三:計算截距 (a)
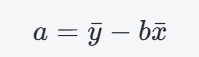
a=53.5
3. 生成線性回歸方程式

解釋為: 父親每增加 1 公分身高, 兒子的預測身高增加 0.7 公分.
4 . 重新計算 R2
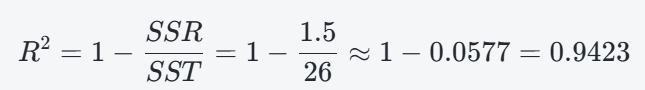
這個新模型不就超準了嗎? 但我們這裡只是建立 model, 並且評估其效果. 還不可以把它視為真正能實用. 下圖可以看到網路謠言版和依照數學原理建立的 model 有何差異? 網路謠言 model 不能解釋我們的資料庫, 但實測會不會更好? 這件事無法反映得出來.