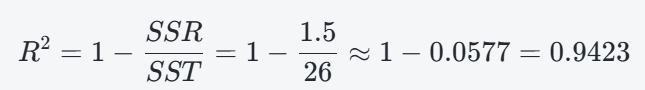Adjusted R2 是 R2 的進階版, 它考慮了模型中變數 (預測因子) 的數量, 懲罰那些濫竽充數的變數, 在多變量回歸 (multiple regression ) 中達到去蕪存菁的效果.
聽起來相當美好. 但我們怎麼知道何時需要它? 要是我們的 model 已經是最好了, 再調整它是否浪費時間? 我們可以先看 R2 的破綻在哪裡?
R2 = 1 – SSR/SST
若 SSR/SST < 1, 表示這是個真分數. 當我新增一個因子, 表現得和平均 (猜的期望值) 一樣好, 真分數 (分子分母加同樣數字) 愈加愈大, R 會愈來愈小. 所以加到沒用的因子, R 會變差 (Adjusted R 變差). 反過來, 如果我們是要減少變數, 也可以預測減掉一個變數是否有感?
Adjusted R² = 1 – [(1 – R²) * (n – 1) / (n – k – 1)]
- 如果加入的變數有貢獻 (提高解釋力), Adjusted R² 會上升.
- 如果加入的變數無貢獻 (p-value 高, 不顯著), Adjusted R² 會下降或持平.
基本上, k 如果增加一個變數, 但它對 R2 又無額外貢獻, 分母的 (n – k – 1) 變小, … 以小學程度的數學可知 Adjusted R² 變小.
順便偷渡一下 n. n -> ∞, (n – 1) / (n – k – 1) -> 1, Adjusted R² 越接近 R² (增加變數的懲罰很小). n 越小, 分母越小, 懲罰項越大, 讓 Adjusted R² 更容易小於 R², 這能更敏感地偵測冗餘變數 (overfitting). 但因為它效力強到難以分辨 feature 好壞, 所以一般不調整 n, 只調整 k.
舉例而言, 現在要估計房價模型. 變數有坪數、屋齡、噪音 (亂數) 三個, k = 3. 統計樣本 n = 100 個. 為了說明方便, 我們先在 Python 固定亂數種子. 做出一堆可以收斂的假資料.
import statsmodels.api as sm
import pandas as pd
import numpy as np
# 步驟 1: 固定亂數種子與資料(同之前)
np.random.seed(0)
n = 100
X = pd.DataFrame({
'坪數': np.random.uniform(20, 200, n),
'屋齡': np.random.uniform(1, 50, n),
'噪音': np.random.normal(0, 1, n)
})
y = 5000 * X['坪數'] - 2000 * X['屋齡'] + np.random.normal(0, 10000, n) # real y安裝 library ( pip install statsmodels) 後, 很多東西都不用算. 包括 OLS (Ordinary Least Squares) model 都會建好. 因為太方便了, 所以定義一個會印出過程的 function.
# 函數:計算 R²/adj_r2、係數和 p-value
def compute_and_compare(model_vars, model_name):
X_sub = sm.add_constant(X[model_vars]) # 加常數項
model = sm.OLS(y, X_sub).fit() # 擬合 OLS 模型
# 計算 R² 和 adj_r2
r2 = model.rsquared
adj_r2 = model.rsquared_adj
print(f"\n{model_name} (變數: {model_vars}):")
print(f" R² = {r2:.4f}")
print(f" Adjusted R² = {adj_r2:.4f}")
# 得到估計係數
params = model.params
print(" 估計係數(params):")
for var in params.index:
print(f" {var}: {params[var]:.2f}")
# 得到每個變數的 p-value
pvalues = model.pvalues
print(" 每個變數的 p-value(顯著性檢定):")
for var in pvalues.index:
print(f" {var}: {pvalues[var]:.4f} (顯著: {pvalues[var] < 0.05})")
print() # 空行分隔讓 3 個變數的 model A 跑一下, 然後讓除掉噪音 (random noise, 不是房子旁邊有噪音), 用只有 2 個變數的 model B 跑一下.
# 步驟 2: 計算模型 A (有噪音)
compute_and_compare(['坪數', '屋齡', '噪音'], "模型 A (有噪音)")
# 步驟 3: 計算模型 B (無噪音)
compute_and_compare(['坪數', '屋齡'], "模型 B (無噪音)")執行上面程式, 會印出:
模型 A (有噪音) (變數: ['坪數', '屋齡', '噪音']):
R² = 0.9745
Adjusted R² = 0.9736
估計係數(params):
const: -949.47
坪數: 4995.64
屋齡: -2003.71
噪音: 42.60
每個變數的 p-value(顯著性檢定):
const: 0.9644 (顯著: False)
坪數: 0.0000 (顯著: True)
屋齡: 0.0000 (顯著: True)
噪音: 0.9655 (顯著: False)
模型 B (無噪音) (變數: ['坪數', '屋齡']):
R² = 0.9744
Adjusted R² = 0.9737
估計係數(params):
const: -947.35
坪數: 4995.64
屋齡: -2003.72
每個變數的 p-value(顯著性檢定):
const: 0.9623 (顯著: False)
坪數: 0.0000 (顯著: True)
屋齡: 0.0000 (顯著: True)我們先關心 Model A 的 R² = 0.9745 > Adjusted R² = 0.9736, 或曰 Adjusted R² < R² , 這個訊號是提示我們的 model 可能有冗餘的變數存在! 調一調會更好! 至於誰是老鼠屎? 這時還看不出來.
但我們也印出了 p-value, 噪音的 p-value = 0.9655 很不顯著, 所以就抓它了! 在 Model B, 我們只用兩個變數.
此時 R² = 0.9744 > Adjusted R² = 0.9737 仍然成立, 或曰 Adjusted R² < R² 就是成立, 那這個時候戰犯要抓誰呢?
const 這個 p-value 值雖然大了點, 但是通常不會是標的. 而且坪數和屋齡的 p-value 都為 0 了, 表示極為顯著! 基本上就沒得挑了. 這也告訴我們指標並非絕對的, 要綜合起來使用.
Model B 的 R² 雖然輸給 Model A (0.9744 < 0.9745), 但我們本來就是抓 overfitting (模型在訓練資料上表現好, 但在未見過的資料上表現差), 所以不會太在意這裡掉了一點. 反而是看 Adjusted R² 從 0.9736 升到 0.9737, 還拔掉一個 p-value 很大的變數, 故改用 model B 是值得肯定的方向.